Modern Library Organization System: Tame Your Digital Chaos
Is your digital workspace a mess? Learn how a modern library organization system, from Dewey to AI, brings order to files & ideas.
Your digital life probably has a junk drawer. It might be called Downloads, Desktop, Final-Final-Use-This-One, or the classic New Folder (3). Somewhere inside it is a PDF you need for work, a slide deck you meant to review, three copies of the same image, and one mystery file with a name like notes_v2_REAL.docx.
That mess feels modern, but the problem isn't new. Libraries ran into it long before laptops existed. As collections grew, simple habits like arranging items by size or by when they arrived stopped working. People needed a reliable way to find things again.
That's what a library organization system really is. It's not just shelves and labels. It's a set of rules that helps humans store information, describe it clearly, and retrieve it fast. Once you look at your digital workspace that way, the chaos gets much easier to fix.
Why Your Digital Files Look Like a Bookstore After an Earthquake
A messy digital workspace usually starts innocently. You save one contract to your desktop because you're in a hurry. Then a few meeting notes land in Downloads. Then screenshots pile up. Then someone sends you “the updated version,” which creates a second copy, and then your own edits become a third.
After a while, finding one file feels like searching a used bookstore where someone sneezed on the shelving plan.
The frustrating part is that you're probably not disorganized. You're just using a system that wasn't designed for growth. A few folders work fine when you have a handful of files. They break down when your work includes PDFs, videos, notes, links, transcripts, drafts, and web research all mixed together.
The old problem hiding inside a new screen
Libraries dealt with this same headache centuries ago. One early organizing system is associated with the Library of Alexandria, and a major catalog milestone came in 1791, when the French government, during the Revolution, created the first library card catalogs using playing cards, according to this .
That's the key idea. People didn't solve information overload by trying harder to remember where things were. They solved it by building systems.
Practical rule: If you regularly say, “I know I saved it somewhere,” your problem usually isn't memory. It's structure.
Your Downloads folder isn't a strategy
One commonly uses one of these accidental methods:
- Search and pray: You type one keyword and hope the file name was sensible.
- Folder sprawl: You build deep folder trees, then forget whether a file belongs in Marketing, Clients, Archive, or Misc.
- Desktop archaeology: You scan thumbnails like a detective in a crime drama, except the crime was committed by Past You.
A real library organization system fixes this by giving each item a logical home and a useful description. That's why even a simple framework can calm things down fast. If you want a practical starting point for the file side of the problem, this guide on is a helpful next step.
The good news is that you don't need to become a cataloging expert. You just need to borrow the same principles librarians have used for a long time: group by subject, name consistently, and make retrieval as important as storage.
The OG Organizers Dewey and LCC Explained
Library organization got serious when collections became too large for informal shelving. Modern systems emerged to handle scale, consistency, and discovery. According to EBSCO's library science overview, the Dewey Decimal Classification was introduced in 1876 and divides knowledge into 10 main classes numbered 000–999, then into smaller divisions and sections. The Library of Congress Classification was put into practice around 1900 and uses 21 subject categories, combining letters and numbers for larger research collections, as outlined in .

Dewey feels like a well-labeled grocery store
Dewey works beautifully when you want broad subjects broken into predictable, browsable chunks. It's similar to a grocery store where every aisle has a category, every shelf narrows the topic, and the layout helps regular people find things without needing a map and a Sherpa.
The technical shape is simple. Dewey uses ten top-level classes, then keeps subdividing them into more specific numeric levels. That structure is one reason it's so approachable in school and public library settings.
A plain-language example:
- 000s might feel like the “general information” aisle
- 500s gather natural science topics
- 900s hold history and geography
You don't need to memorize those shelves to understand the lesson. Dewey gives each subject a clear numeric address.
LCC feels like a university archive
The Library of Congress Classification, often shortened to LCC, is built differently. LibreTexts explains that LCC uses an alphanumeric call number format that starts with 1–2 letters for broad subject areas and then adds numeric subclasses for more precise placement in .
If Dewey is the grocery store, LCC is the research campus archive. It's less about casual browsing and more about precision. You can place highly specific material into a structure that supports large, complex collections.
Dewey says, “Let's help people browse.”
LCC says, “Let's help researchers pinpoint exactly the right thing.”
What digital workers should steal from both
You don't need call numbers on your laptop. You do need the ideas underneath them.
Here are the principles worth keeping:
- Hierarchy matters: Broad categories should break into narrower ones.
- Subjects beat randomness: Group information by meaning, not by when you happened to save it.
- Consistency wins: A good system works even when your collection gets bigger.
- Retrieval is the goal: Organization isn't decoration. It's a finding tool.
That's why old-school library science still feels fresh. The labels change. The logic doesn't.
Beyond the Bookshelf Modern Digital Systems
The modern challenge isn't just shelving books by subject. It's managing mixed-format collections across print, e-books, databases, and local digital files in one discoverable system. That's a gap many introductions miss, as noted in . The fundamental question people ask is simpler and more urgent: how do I organize everything so I can find the right item quickly?
That's where digital methods split into three camps: folders, tags, and hybrids.
Folders are clear until they trap you
Folders are familiar. Everyone understands them. They create a visual hierarchy that feels tidy and comforting, a bit like putting socks in one drawer and T-shirts in another.
The trouble starts when one item belongs in more than one place. A research brief might fit under Client Work, Market Research, Strategy, and Q3 Planning. A folder makes you choose one home, even when the file clearly has several identities.
Tags are flexible until they get weird
Tags solve the “one item, many meanings” problem. You can label the same document with project, topic, status, client, and format. That's much closer to how humans think.
But tags can also drift into nonsense if nobody defines them. One week you tag a note meeting. The next week it becomes meetings. Then team-meeting. Then calls. Congratulations, you've invented chaos with extra steps.
Hybrid systems usually work best
A hybrid setup combines a light folder structure with disciplined metadata or tagging. That gives you both a stable home and flexible ways to retrieve the same item later.
Here's the trade-off in one view:
If you're designing a modern library organization system for work, hybrids tend to match reality best. Users don't just store documents; they manage notes, chats, links, PDFs, screenshots, recordings, and draft ideas together. A good usually reflects that by combining structure with discoverability.
The practical question isn't “folders or tags?” It's “what combination helps me find this again fast without forcing me to think too hard while saving it?”
The Magic Ingredient Metadata and Search
You can usually find an email from years ago faster than a PDF from last Tuesday. That's not because email is magical. It's because email systems store and use a lot of metadata.
Metadata is the information about the item. For a file, that might include its name, creator, date, file type, project, topic, and any labels you add yourself. Think of it as a digital name tag.

Why location matters less than description
A folder tells you where something lives. Metadata tells you what it is.
That shift changes everything. If a note is tagged with a client name, project stage, and topic, you can retrieve it from several angles. You no longer have to remember the exact path where you saved it.
A file called draft2.pdf inside a random folder is nearly useless. The same file with useful metadata becomes searchable by topic, date, context, and purpose.
Key idea: Strong search depends on strong descriptions. The file name alone usually isn't enough.
Better search starts with better labels
The simplest metadata fields to improve are the ones you control:
- Titles: Use plain names that mean something later, not just today.
- Tags: Add a few stable labels for project, topic, or status.
- Dates: Keep date formats consistent if you include them in file names.
- Context notes: A short summary often saves more time than a perfect folder path.
This is also why smarter retrieval tools feel different from old-fashioned keyword search. Instead of matching only exact terms, some systems use richer context to understand what you meant. If you're comparing approaches, this breakdown of is worth reading.
The fundamental upgrade isn't just storing files neatly. It's making your information legible to search.
Building Your Digital Library with Zemith
A useful digital library doesn't ask you to choose between structure and flexibility. It needs both. That's where tools built around a central library model make sense, especially if your work lives across documents, notes, research, and ongoing conversations.

Think in collections, not loose files
A practical way to translate library science into digital work is to separate your information into two layers:
- A central library: This holds the core material you want available and searchable.
- Project collections: These gather related items around a specific task, topic, or outcome.
That model mirrors what librarians do with a main collection and specialized groupings. It also reflects how real work happens. A research report usually isn't just one PDF. It's the PDF, your notes, related articles, a transcript, maybe a recorded meeting, and a thread of follow-up questions.
Zemith uses this kind of setup through its Library and Projects features. The Library acts as a central repository for documents and chats, while Projects group materials around a shared context and knowledge base. In plain terms, that means your information doesn't just sit there. It stays connected to the work you're doing with it. If you often need to extract usable text from source material before organizing it, this guide on fits naturally into that workflow.
Why AI changes the old library model
Traditional cataloging relies on humans to describe items well. Digital systems still need that, but AI adds another layer. It can help interpret the actual content of your files rather than depending only on folder names and manual labels.
That matters when your collection includes messy real-world inputs:
- meeting transcripts
- scanned PDFs
- draft documents
- web research
- notes with half-finished thoughts
- screenshots with buried context
An AI-assisted library organization system can help you surface meaning from those materials instead of treating them as dumb attachments.
A simple setup that works
If you're building your own digital library, keep the architecture boring on purpose. Boring is good. Boring scales.
Try this:
Create a small set of top-level collections
Use broad buckets like Work, Research, Personal Learning, and Admin.Use projects for active work
Group the files, notes, and conversations that belong together, even if they come from different formats.Tag sparingly
Pick a few reliable dimensions such as topic, client, status, or content type.Let search do heavy lifting
Don't force yourself to remember where every item lives if your system can retrieve by context.
The best digital library is not the one with the prettiest folder tree. It's the one that returns the right material when you need it, without making you play memory games.
That's the modern evolution of library thinking. The old systems taught us how to classify at scale. Digital work adds metadata, cross-linking, and content-aware retrieval. Put together, those pieces turn a pile of files into a usable knowledge environment.
Governance and Best Practices So It Doesnt Get Messy Again
A good system can still collapse if you feed it chaos every day. Maintenance doesn't need to be complicated, but it does need to exist. Think of your digital library like a Tamagotchi for grown-ups. Ignore it too long, and something starts blinking sadly.
The fix is governance. Not the scary boardroom kind. Just a few habits everyone follows.

The maintenance checklist that saves future you
- Use one inbox location: New files should land in a single triage spot first. Don't file things emotionally.
- Standardize names: Pick a naming pattern and stick to it. Consistency beats cleverness.
- Limit your tags: A shorter approved tag list works better than endless creativity.
- Archive on purpose: Old material should move to an archive instead of hanging around active spaces forever.
- Review weekly: A quick cleanup prevents a slow slide back into disorder.
- Document the rules: If a team shares the system, write down the basics so everyone files information the same way.
Accuracy matters too
A clean library isn't only easy to search. It's also more trustworthy. If you work in regulated, technical, or evidence-heavy environments, data integrity principles matter a lot. A useful reference is this overview of , which frames why records should be attributable, legible, contemporaneous, and consistent. Even outside a lab, those ideas translate surprisingly well to document handling.
Messy organization creates two problems at once: you lose information, and you lose confidence in what you found.
For teams that want a broader operating playbook, these are a solid companion to the checklist above.
A library organization system stays useful when the rules are simple enough to follow on a busy Tuesday. That's the true test.
Conclusion Your Personal Librarian Is an AI
The interesting twist here is that library science never stopped being relevant. We just changed the shelves.
The same core ideas still work. Group information by meaning. Use consistent structure. Add useful descriptions. Make retrieval the point. Whether you're organizing books, PDFs, meeting notes, or research clips, the job is the same: help a human find the right thing quickly and trust that it's the right thing.
That's why a modern library organization system matters so much. It doesn't just make your workspace look cleaner. It reduces friction. It helps you connect ideas across projects. It turns “I know I saw that somewhere” into “I've got it.”
AI makes that leap more practical. Instead of acting like a passive cabinet, your digital library can become something closer to a working research assistant. It can help you search by meaning, connect related material, and surface context you would've forgotten to look for.
That's a big shift. The old dream of the library was access. The new dream is access with understanding.
If your current setup depends on memory, luck, and an increasingly haunted Downloads folder, it may be time for an upgrade. Borrow the principles librarians figured out long ago, then apply them to the way you work now.
If you want one workspace for documents, research, projects, and AI-assisted retrieval, take a look at . It applies the logic of a well-run library to modern digital work, so you can spend less time hunting for files and more time using what you've already found.
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
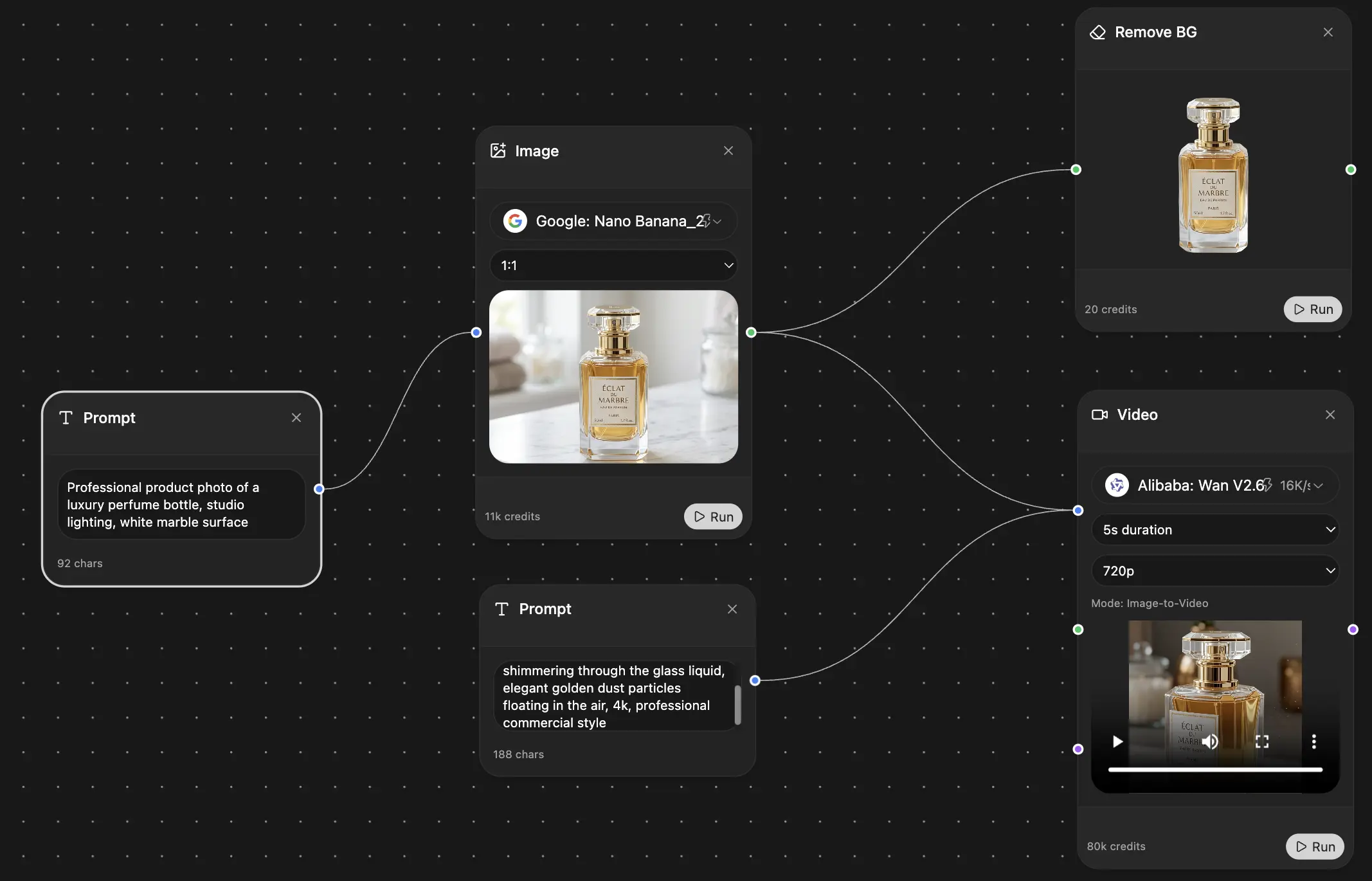
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691