Translation Korean to English: A Practical AI Workflow
Ditch copy-paste. Learn a practical AI-powered workflow for translation Korean to English, handling grammar, nuance, and QA like a pro with modern tools.
A Korean document lands in your inbox at 4:12 p.m. It's a PDF. Some pages are clean text, some are screenshots, one page looks like it was faxed during a thunderstorm, and someone has kindly added, "Can you get this into polished English today?"
A common first step involves copying a chunk into a free translator, receiving a partially decipherable result, and then manually correcting imperfections. That works for a quick gist. Its effectiveness diminishes when the document is critical.
The problem isn't just the translation engine. It's the assumption that translation korean to english is a one-click task. It isn't. It's a document workflow, a review workflow, and a meaning-preservation workflow. If you treat it like copy-paste, you'll spend more time fixing the output than you saved by automating it.
Beyond Copy-Paste Your New Translation Mindset
A Korean document rarely arrives as clean, translation-ready text. It arrives as a working file with formatting problems, mixed terminology, missing context, and a deadline attached. The quality of your English output depends less on the first model you choose and more on how you manage the document from intake to review.

That shift matters with Korean because the hard part is often hidden. Subjects get omitted. Formality carries business meaning. Headings, table labels, and short UI strings can become ambiguous once they are separated from the page they came from. A free text box can give you a draft, but it cannot manage context, terminology decisions, or revision history.
I handle translation korean to english as a production workflow, not a single prompt. That means I want one place to extract text, test a few translation approaches, compare outputs, keep notes on terminology, and refine the final copy without losing the source. A multi-model workspace such as Zemith is useful here because it supports the whole job. It is not just a place to paste text and hope.
What the copy-paste habit misses
The weak results I see in real projects usually come from process failures:
- Text is pasted in broken chunks: sentence boundaries shift, headings lose scope, and list items get detached from the point they modify.
- The first fluent draft gets approved: readable English hides dropped qualifiers, softened obligations, and wrong tone.
- No one records decisions: product terms, department names, and repeated phrases change from page to page.
- Review happens too late: by the time someone compares against the Korean, the formatting is already rebuilt and expensive to fix.
Pure machine translation is cheap and fast. It is also fragile. Human translation agencies are safer for high-risk material, but the cost is hard to justify for every internal report, slide deck, support article, or vendor document. The practical middle ground is a hybrid process. Use AI for speed, then add structured checks where Korean-to-English errors usually appear.
The better question
The useful question is not which engine is best in the abstract. The useful question is how to build a repeatable path from messy source file to dependable English.
That is why prompt quality matters, but only as one part of the system. A clear prompt improves output. A weak process still creates rework. If you want to tighten the way you instruct models, this is a solid reference. For day-to-day translation work, I also recommend building the habit of so you can clarify intent, compare alternatives, and challenge suspicious phrasing before it reaches final review.
One rule has saved me a lot of cleanup time. If the file is longer than a short email, treat translation as document operations plus language review. Once you adopt that mindset, the work gets faster, more consistent, and much easier to hand off or repeat.
Getting Your Korean Text Ready for AI
A Korean PDF lands in your inbox at 4:30 p.m. It looks simple until you open it. Half the text is trapped in images, the table headers repeat on every page, and the product names switch between Korean, English, and internal shorthand. If you paste that straight into a model, you are not starting translation. You are starting cleanup after a preventable mistake.
Good Korean to English work starts with extraction, structure, and term control. I treat this stage like preflight. If the source is unstable, every later step gets slower, including review, formatting, and stakeholder approval.
Korean and English also expand differently on the page. English often takes more room, so labels wrap, tables break, and subtitles drift out of time. That matters long before final QA. It affects how you chunk the text, what you preserve as a single unit, and whether a designer or PM needs to plan for layout fixes.
Extract first, then repair the structure
If the source lives in a scanned PDF, slide image, or screenshot-heavy report, start by pulling the text out cleanly. Manual retyping only makes sense for very short files.
For document-heavy work, use a repeatable extraction step before you write any translation prompt. A practical helps because OCR errors are rarely random. They usually break the same things: sentence boundaries, tables, headers, and mixed-language strings.
Check the extracted text for:
- Broken sentences: line breaks inserted in the middle of clauses
- Header pollution: repeated headers or footers mixed into body text
- Table drift: values detached from the row or column they belong to
- Mixed scripts: model numbers, acronyms, names, and Korean terms that must stay intact
This part is tedious. It also saves hours.
Clean the source like someone else has to reuse it
Pretty formatting is not the goal. Structural reliability is.
My working sequence is simple:
Separate headings from body copy
Korean headings are often short. If OCR merges them into the first sentence, the model tends to flatten the section and miss the document hierarchy.Restore complete sentences
Join line-wrapped fragments so the model sees syntax, not scraps.Pull out repeated terms
List product names, department names, legal citations, and technical vocabulary before translation starts. In Zemith, a shared workspace is helpful. One model can extract terms, another can draft the translation, and the glossary stays visible during review.Tag high-risk passages
Contracts, medical content, patent claims, and formal academic arguments need stricter review than a blog draft or meeting summary.
Clean input does not guarantee a strong translation. Dirty input almost guarantees a messy one.
Prompting starts after document prep, not before
A weak prompt can cause problems, but I see more damage from bad source handling than from bad wording in the prompt itself. If the text is fragmented, duplicated, or missing labels, even a good model will guess.
Once the source is stable, give the model instructions that match the job. The useful fields are usually enough:
- Document type: contract, abstract, slide deck, support article, product spec
- Audience: internal team, customer, executive reviewer, regulator
- Tone target: neutral, formal, concise, plain business English
- Term handling: preserve Korean names, transliterate selected items, keep glossary terms consistent
- Output format: paragraph translation, side-by-side table, reviewer notes, flagged ambiguities
The difference is practical. Instead of a generic English draft, you get something that can move through review with fewer edits. For teams building a repeatable setup, this is useful because it focuses on instruction design you can apply across real files, not just single text-box examples.
Prepare for an end-to-end workflow, not a one-off paste
This is the point many teams miss. Translation is not only a language task. It is a document operation, a terminology task, and a review task tied together.
A tool-assisted workflow makes that manageable. In Zemith, for example, I can extract text, clean it, generate a first-pass translation, compare revisions across models, and keep notes on terms that need human review. That hybrid approach does not replace expert linguists for high-risk material. It does make routine Korean to English work far more controllable than raw machine translation, without sending every file to a full-service agency.
If the source is prepared properly, the model has a fair chance to do good work. If it is not, you spend the rest of the project correcting errors that were baked in before translation even began.
Choosing Your AI Translation Strategy
Using one translation model for every Korean document is like using one kitchen knife for every ingredient. You can do it. You probably shouldn't.
What matters isn't finding a universally "best" model. It is matching the model behavior to the job, then checking the result against alternatives when the stakes justify it.
What machine translation handles well
Recent research gives a useful reality check. A 2024 ERIC-indexed study on Korean-to-English machine translation found high semantic performance on passive constructions, including 83.67% (82/98) lexical performance and 96.93% (95/98) in one comparison set, with adversity constructions reaching 96.22% (51/53) and 98.11% (52/53) in the systems shown according to the .
That matters because passive and adversity structures are not easy mode. Modern MT can clearly do real work here.
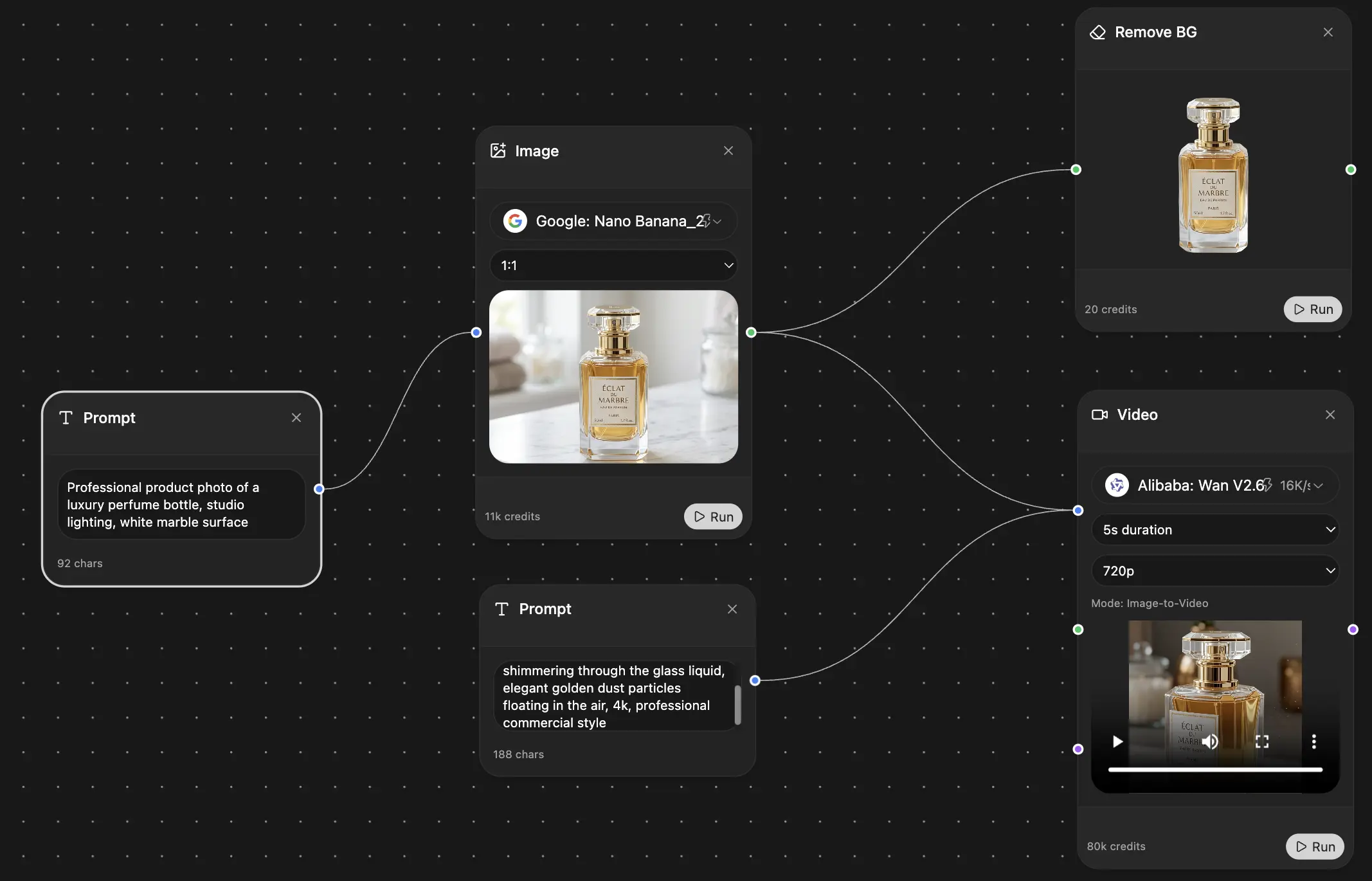
Later in the process, it's useful to compare what different systems do with the same sentence. Some lean literal. Some smooth aggressively. Some preserve structure better than tone. If you're evaluating options or building a broader toolkit, an organized helps because translation rarely happens in isolation from note-taking, rewriting, and document handling.
A quick visual example helps here:
Where single-model trust breaks down
A different Korean-to-English study on relative clauses reported that more than 90% of translated relative clauses were semantically accurate overall, including 94.91% for one system and 96.31% for another. But the same analysis also reported 9.55% and 8.77% rates of semantically or grammatically inaccurate outputs, plus smaller shares of non-targeted but still acceptable forms, in the KCI study on Korean-to-English relative clause translation.
That's the trade-off in one paragraph. The outputs are often good. They are not safe to accept blindly.
A practical comparison mindset
When I evaluate Korean-to-English output, I usually care about four things more than "overall fluency."
High accuracy on research benchmarks is encouraging. It is not permission to skip review.
A better strategy than "pick one and pray"
For low-risk text, a strong first-pass model is enough. For anything operational, I prefer a multi-model comparison workflow.
That can look like this:
- First pass with a general model for full-document coverage
- Second opinion on ambiguous paragraphs that contain legal qualifiers, technical descriptions, or compressed formal Korean
- Targeted rewrite pass for tone, readability, or executive-summary polish
- Source comparison pass to catch omissions and false confidence
Modern AI workflows offer an advantage over the old text-box experience. You don't need to marry one engine. You need a process for checking where one engine may be overconfident.
And yes, overconfidence is the villain here. A bad translation that looks bad is easy to fix. A bad translation that sounds polished is the one that gets approved by accident.
Decoding Grammar Honorifics and Cultural Nuance
This is the part that separates "readable" from "publishable."
Generic tools often do fine with plain statements. They get shaky when Korean asks the reader to infer the subject, interpret a hierarchy, or carry social meaning through verb endings and particles. That becomes a serious issue in high-stakes material. One major gap in online translation guidance is exactly this problem in legal, medical, and academic documents, where honorifics, omitted subjects, and context-dependent particles can be mistranslated and alter meaning, as noted in .
Honorifics are not decoration
Korean politeness carries meaning. It tells you about status, relationship, formality, and intent. English doesn't encode those layers the same way, so a direct conversion often sounds either too stiff or too casual.
A common mistake is flattening everything into neutral business English. That may sound fine, but it can erase whether the original was deferential, formal, warm, procedural, or distancing.
For example:
- A formal executive announcement may come out sounding like a friendly team update.
- A customer notice may lose its respectful tone and become blunt.
- A legal statement may sound softer than the Korean intended.
Omitted subjects create fake certainty
Korean often leaves the subject unstated because context carries it. English usually wants the subject named. The problem is that machine translation sometimes fills in the blank with too much confidence.
If the source implies "the company," "the department," or "the researcher," but doesn't explicitly say it, the English output can choose the wrong actor and make the sentence narrower than the original.
When the Korean leaves room for interpretation, your English shouldn't quietly pretend there was no ambiguity.
Idioms need interpretation, not obedience
Literal translation is where things get unintentionally funny. If someone translates 김칫국부터 마시지 말라 as "don't drink the kimchi soup first," the words are technically there, but the meaning isn't. In context, the English idea is closer to "don't get ahead of yourself."
That doesn't mean every idiom needs a Western equivalent. It means you should ask: what job is this phrase doing here?
A working revision approach
For nuanced Korean, I like a sentence-level review loop after the first draft. Not full retranslations. Targeted refinements.
Useful revision prompts include:
- Make this more formal without sounding archaic
- Preserve ambiguity if the subject is implied in Korean
- Rewrite this as natural legal English
- Explain whether this sentence implies obligation, suggestion, or courtesy
- Keep the meaning, but remove literal idiom wording
A semantic review tool can help at this stage, especially if you're checking whether the English paraphrase still matches the source intent. If you need a grounding concept for that, is a useful lens.
The test I actually use
Read the English and ask two questions:
- Who seems to be speaking?
- What relationship does the sentence imply?
If the answer feels wrong, the translation probably flattened nuance that mattered.
That sounds simple, but it's how you catch the weird cases. The sentence may be grammatically fine and still misrepresent authority, politeness, or responsibility. In Korean-to-English work, those are not cosmetic details. They're meaning.
Your Quality Assurance Checklist for Translation
A decent draft is not the finish line. QA is the part that saves you from publishing something polished and wrong.
For Korean-to-English work, I keep the checklist short on purpose. Long QA lists look impressive and get ignored. A few sharp checks catch most of the costly mistakes.
The four-pass review
Semantic pass
Read one paragraph of English, then compare it against the Korean. Don't compare word by word. Compare claims, conditions, and implications.
Look closely at:
- Negation: Did "not," "unless," or "except" survive?
- Scope: Did a qualifier get attached to the wrong phrase?
- Agency: Did the English assign an actor that the Korean left implicit?
Completeness pass
This catches quiet omissions. They happen more than people expect, especially after OCR extraction or when the source has bullet-heavy formatting.
Scan for:
- Dropped list items
- Missing parenthetical details
- Vanished sentence endings
- Short Korean phrases that got absorbed into neighboring lines
Consistency pass
Translation memory software is great when you have it. If you don't, manual consistency review still matters.
Create a mini glossary with repeated terms such as product names, department names, technical nouns, legal references, and recurring verbs. Then check whether each term stayed stable across the document.
Tone and collocation check
A sentence can be accurate and still sound wrong to an English reader. This usually shows up in collocation. The words are all legal English words, but they don't naturally belong together.
If you want a quick refresher on why phrases like "perform a decision" or "strong rain" feel off, is a handy reference.
Quality check: Read the English aloud. If you wouldn't say it in a meeting, report, or customer email, it probably needs another pass.
A compact QA table
Organize the review or you'll lose the thread
The worst QA setup is scattered tabs, duplicate files, and mystery versions named Final_v2_REAL_final. I've seen enough of those to know "REAL final" is never the final.
Keep the source, extracted text, draft translations, glossary notes, and edited version together. If you're refining writing after translation, a practical helps because revision quality depends heavily on seeing versions side by side instead of guessing what changed.
My cutoff for escalating to a human specialist
Some documents should not rely on AI plus light editing. If the text contains legal liability, medical instructions, patent claims, ethics review language, or publication-critical academic argumentation, specialist review is worth it.
For everything else, a disciplined hybrid workflow does surprisingly well. The key phrase there is disciplined. AI saves time. QA protects meaning.
Conclusion You're a Workflow Architect Now
Good Korean-to-English work doesn't come from a better copy-paste habit. It comes from a better system.
That system starts with source cleanup. It gets stronger when you choose an AI strategy instead of accepting the first output that sounds fluent. It becomes reliable when you review for nuance, missing meaning, and consistent terminology. By the end, you're not just translating. You're managing a chain of decisions that turns messy source material into usable English.
The broader shift in translation is moving away from one-off text boxes and toward integrated, multi-format workflows where people need to translate documents, preserve formatting, and manage terminology across projects, as reflected in . That's a better fit for how real teams work.
What works and what doesn't
What works:
- Preparing the source before translation
- Comparing outputs when the sentence is tricky
- Editing for tone and English readability
- Running a real QA pass before delivery
What doesn't:
- Trusting one draft because it sounds smooth
- Ignoring omitted subjects and honorific nuance
- Translating directly from messy OCR output
- Treating a document project like a text-box task
The useful mindset change
If a Korean document lands on your desk now, the job isn't "get English words out of this file." The job is to create a repeatable path from source to verified meaning.
That sounds less glamorous than "AI translates everything instantly." It is also far more useful.
And that's where the biggest productivity gains come from. Not from replacing judgment, but from giving judgment a cleaner process. You can move fast without being careless. You can save money without settling for agency-level overhead on every single file. You can build a workflow that gets better each time because your prompts, glossaries, and QA habits become reusable.
That's a significant upgrade in translation korean to english. You stop being a person throwing text at a tool. You become the person designing the system that makes the tool dependable.
If you want one place to handle document extraction, multi-model drafting, note-based revision, and side-by-side project organization, is built for exactly that kind of AI workflow. It works especially well when translation is part of a bigger research, writing, or localization process instead of a one-off text box task.
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691