
KI-Modelle testen: Der einzige Leitfaden, den Sie brauchen (2025)
Lernen Sie, wie Sie KI-Modelle wie ChatGPT, Claude und Gemini mit unserem 6-Schritte-Framework testen. Vergleichen Sie KI-Modelle nebeneinander mit echten Aufgaben—keine technischen Fähigkeiten erforderlich.
KI-Modelle testen: Der einzige Leitfaden, den Sie wirklich brauchen
Ich habe vor etwa einem Jahr damit begonnen, KI-Modelle obsessiv zu testen, als ich Zemith baute. Nicht, weil ich ein ML-Forscher bin—das bin ich nicht. Sondern weil ich immer wieder von dem Hype enttäuscht wurde.
Alle sagten, GPT-4 sei das Beste. Dann kam Claude heraus und die Leute sagten, das sei das Beste. Dann Gemini. Dann würde ein neues Modell erscheinen und plötzlich war das der König. Die Torpfosten bewegten sich ständig, und ich erkannte: Wenn Sie wissen wollen, welches KI-Modell tatsächlich für Ihre Bedürfnisse funktioniert, müssen Sie KI-Modelle selbst testen.
Nicht Benchmarks lesen. Nicht Marketingversprechen vertrauen. Sie tatsächlich testen.
Dies ist kein technischer Leitfaden über Perplexity-Scores oder BLEU-Metriken. Dies ist, wie echte Menschen—Gründer, Kreative, Entwickler, jeder, der täglich KI nutzt—KI-Modelle bewerten und herausfinden sollten, welches liefert.
Während einige Leute lieber Diagramme zum Vergleich betrachten, unterscheidet sich das tatsächliche Ergebnis in der realen Welt oft erheblich. Der einzige Weg, sicher zu wissen, was und wie die Modellantwort ist, ist durch tatsächliche Nutzungstests.
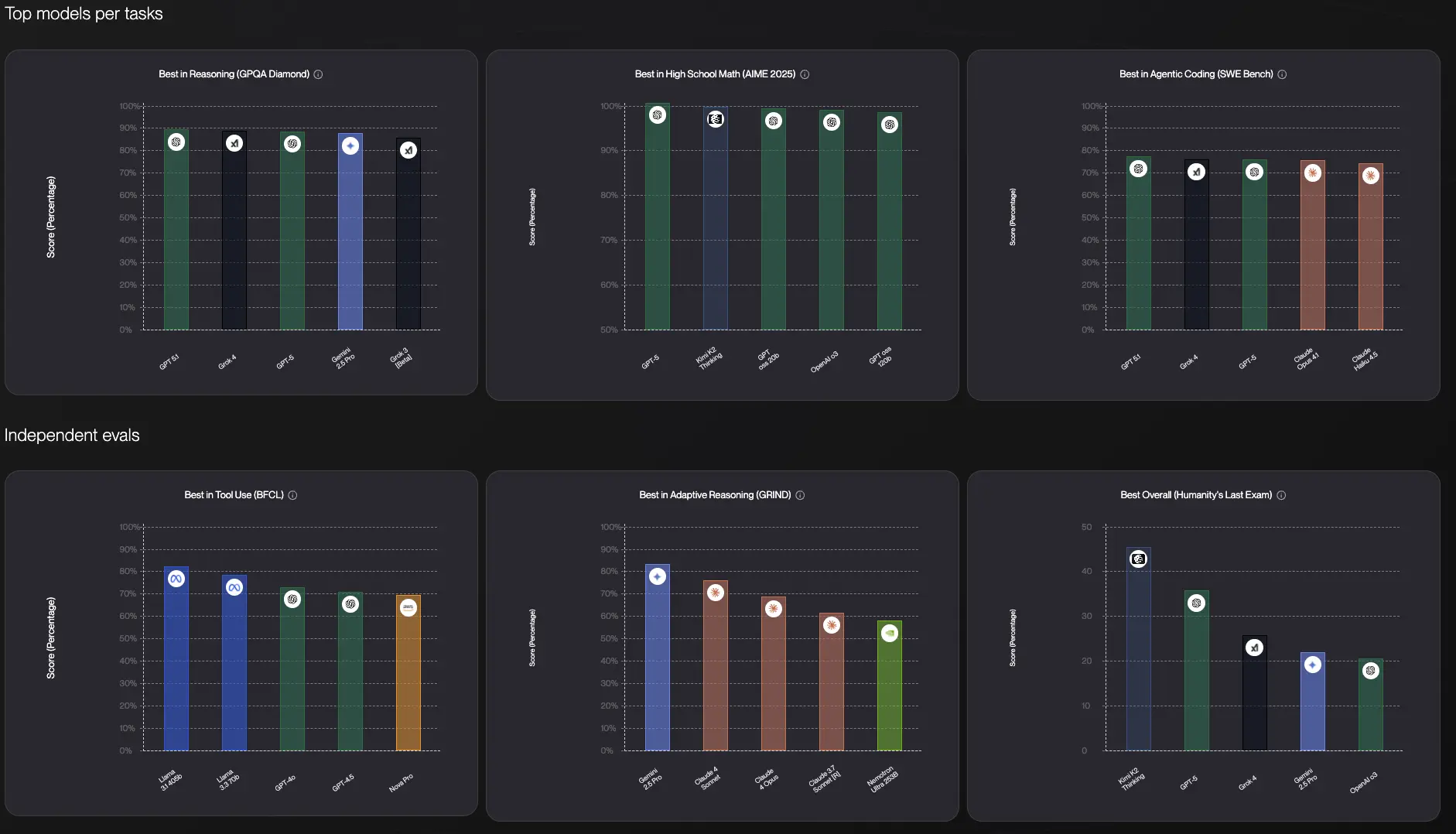
Warum das Testen von KI-Modellen selbst nicht verhandelbar ist
Das habe ich auf die harte Tour gelernt: KI-Modell-Benchmarks sind für Ihre tatsächliche Arbeit im Grunde nutzlos.
Ein Modell mag einen akademischen Test dominieren, aber das sagt Ihnen nicht, ob es E-Mails in Ihrer Stimme schreibt, das Jargon Ihrer Branche versteht oder die seltsamen Edge-Cases behandelt, mit denen Ihr Unternehmen täglich zu tun hat.
Ich lese seit Monaten Reddit-Diskussionen über KI-Modelle, und es gibt dieses wiederkehrende Thema: Jemand fragt "welche KI soll ich verwenden?" und die Antworten sind überall. Eine Person schwört, Claude sei für Coding unschlagbar. Ein anderer sagt, ChatGPT sei kreativer. Jemand anderes besteht darauf, dass Gemini am genauesten sei. Sie haben alle recht und alle unrecht.
Nachdem ich diese Modelle tausende Male getestet habe, ist hier die Wahrheit: Es gibt kein einziges "bestes" KI-Modell. Jedes hat unterschiedliche Stärken, und diese Stärken sind je nachdem, was Sie tatsächlich versuchen zu tun, unterschiedlich wichtig.
ChatGPT könnte Ihnen kreative, ansprechende Inhalte geben, die menschlich wirken. Claude könnte strukturiertere, durchdachtere Antworten liefern, die perfekt für Analysen sind. Gemini glänzt bei faktischer Recherche und hat ein enormes Kontextfenster für lange Dokumente.
Der einzige Weg zu wissen, welches Modell für Sie am besten funktioniert, ist, KI-Modelle mit Ihren tatsächlichen Anwendungsfällen zu testen. Nicht hypothetische. Nicht generische Prompts. Ihre echte Arbeit.
Die Fragen, die alle tatsächlich stellen
Bevor wir darauf eingehen, wie man KI-Modelle testet, lassen Sie mich die Fragen ansprechen, die ich ständig auf Reddit und in DMs sehe:
"Kann ich nicht einfach ChatGPT für alles verwenden?"
Sie könnten, aber Sie würden viel liegen lassen. Es ist wie ein Schweizer Taschenmesser zu verwenden, wenn Sie manchmal wirklich einen richtigen Schraubendreher brauchen.
"Reichen die Benchmarks nicht aus?"
Nicht wirklich. Ich sah einen Reddit-Thread, in dem jemand darauf hinwies, dass Claude bei einem Benchmark niedriger abschnitt, aber ihnen viel bessere Code-Erklärungen gab. Benchmarks messen, was Forscher für wichtig halten, nicht was Ihnen tatsächlich hilft, Arbeit zu erledigen.
"Wie weiß ich überhaupt, ob eine Antwort besser ist als eine andere?"
Das ist die echte Frage, und ehrlich gesagt ist es einfacher als Sie denken. Wenn Sie die Antwort verwenden können, um Ihre Aufgabe besser, schneller oder mit weniger Frustration zu erledigen—das ist Ihre Antwort.
"Ist das nicht nur Überdenken?"
Vielleicht, wenn Sie KI gelegentlich verwenden. Aber wenn Sie ein Unternehmen aufbauen, täglich Inhalte schreiben oder sich für echte Arbeit auf KI verlassen? Testen ist kein Überdenken—es ist Sorgfaltspflicht.
Wie man KI-Modelle testet: Das 6-Schritte-Framework
Vergessen Sie technische Metriken. So testen Sie Sprachmodelle tatsächlich und vergleichen KI-Modelle auf eine Weise, die wichtig ist:
1. Beginnen Sie mit Ihren tatsächlichen Aufgaben
Testen Sie KI-Modelle nicht mit generischen Prompts wie "schreibe eine Geschichte über eine Katze". Das ist nutzlos.
Stattdessen nehmen Sie drei bis fünf Aufgaben, die Sie tatsächlich regelmäßig erledigen:
- Entwerfen Sie eine bestimmte Art von E-Mail, die Sie oft senden
- Fassen Sie ein typisches Dokument aus Ihrer Arbeit zusammen
- Generieren Sie Ideen für Ihre tatsächlichen Projekte
- Schreiben Sie Code für etwas, das Sie tatsächlich bauen
- Beantworten Sie eine Kundensupport-Frage, die Sie erhalten haben
Je spezifischer und realer diese Aufgaben sind, desto besser wird Ihre KI-Modell-Bewertung sein.
2. Verwenden Sie identische Prompts über verschiedene KI-Modelle hinweg
Das ist entscheidend, wenn Sie KI-Modelle testen. Nehmen Sie genau denselben Prompt und führen Sie ihn durch ChatGPT, Claude, Gemini und welche anderen Modelle Sie auch in Betracht ziehen.
Ändern Sie nicht die Formulierung. Passen Sie ihn nicht für jedes Modell an. Verwenden Sie identische Eingaben, damit Sie die Ausgaben fair vergleichen können.
Als ich das zum ersten Mal bei Zemith tat, war ich schockiert. Für kreatives Brainstorming gab mir ChatGPT konsistent interessantere Ansätze. Für die Analyse von Daten oder das Aufbrechen komplexer Themen war Claude klarer und organisierter. Für faktische Recherche mit aktuellen Informationen zog Gemini voraus.
Ich sah einen großartigen Reddit-Post, in dem jemand alle drei Modelle mit demselben Rätsel testete: "Wie ist es möglich, dass der Vater des Sohnes eines Arztes kein Arzt ist?" Alle drei hatten recht, aber ihre Ansätze waren völlig unterschiedlich. Claude gab die detaillierteste Aufschlüsselung und wies sogar auf potenzielle Vorurteile in unserer Denkweise über das Problem hin. ChatGPT war prägnant und auf den Punkt. Gemini gab die richtige Antwort mit einer kurzen Erklärung.
Alle richtig, alle nützlich, aber jeder mit einem anderen Stil. Dieser Unterschied ist wichtig, wenn Sie entscheiden, welches Sie für Ihre tatsächliche Arbeit verwenden.
3. Vergleichen Sie nebeneinander, nicht aus dem Gedächtnis
Das menschliche Gedächtnis ist schrecklich bei Vergleichen. Wenn Sie heute ChatGPT und morgen Claude testen, werden Sie die Nuancen vergessen, was jeder sagte.
Genau deshalb habe ich FocusOS auf Zemith gebaut, weil der Versuch, sich zu merken, welches Modell was über mehrere Tabs hinweg sagte, ein Albtraum ist.
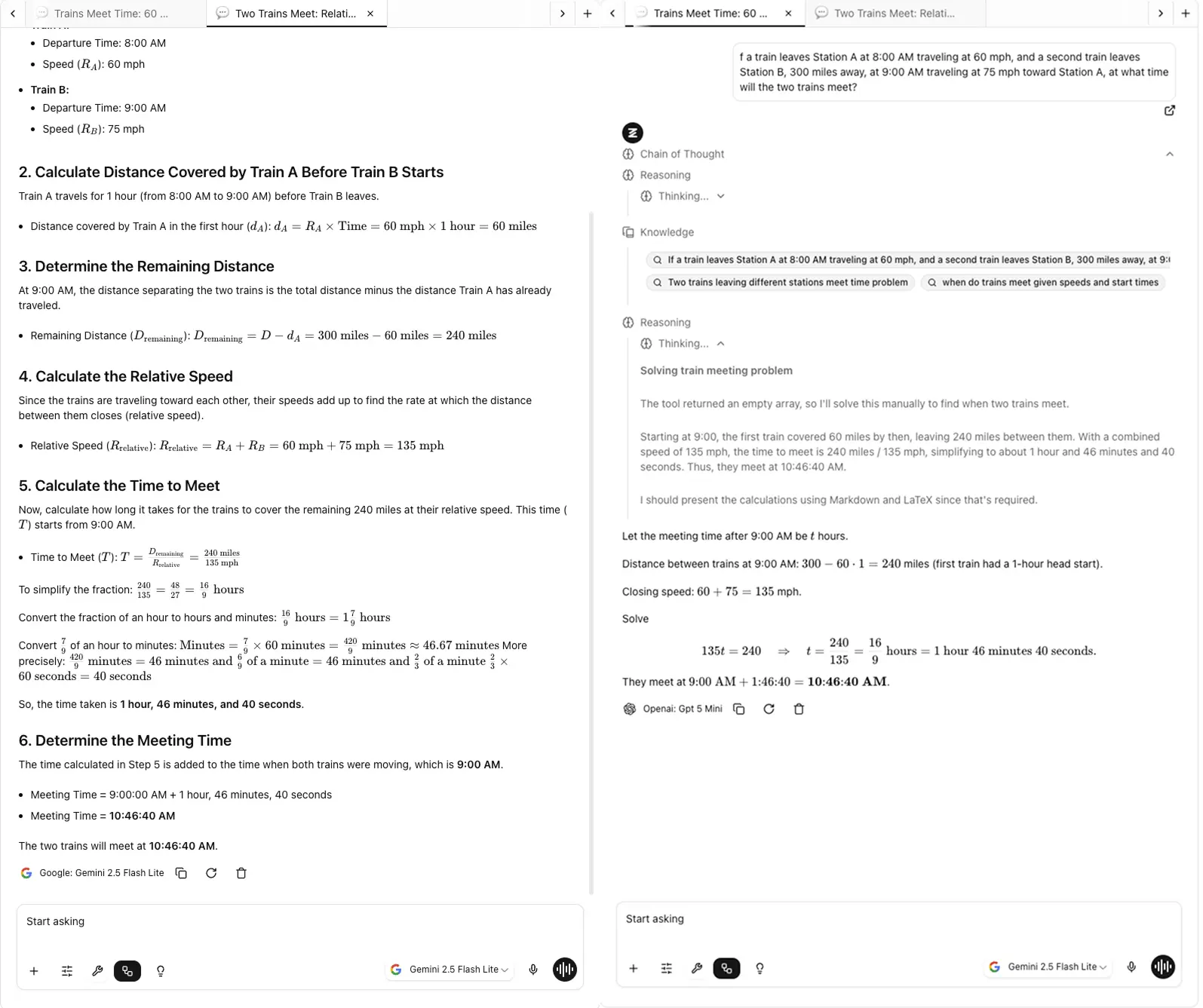
Bei Zemith habe ich Focus OS mit einem Chrome-ähnlichen Tab-System entworfen, damit Sie schnell zwischen Tabs wechseln können, ohne den Kontext von einer Seite zu verlieren, ohne Browser-Tabs jonglieren zu müssen, ohne den Überblick zu verlieren, welche Antwort von welchem Modell kam.
Wenn man Antworten zusammen betrachtet, werden Muster sichtbar, die man sonst übersehen würde:
- Welches Modell beantwortet tatsächlich Ihre Frage vs. welches schwafelt?
- Welches behält Ihren bevorzugten Ton bei?
- Welches gibt Ihnen Informationen, die Sie tatsächlich verwenden können?
Dies ist der beste Weg, KI-Modelle zu testen, weil Sie die Unterschiede in Echtzeit sehen, nicht versuchen, sie aus dem Gedächtnis zu rekonstruieren.
4. Testen Sie auf Konsistenz und KI-Modellleistung
Führen Sie denselben Prompt einige Male durch jedes Modell. KI-Modelle sind probabilistisch—sie geben nicht immer dieselbe Antwort.
Einige Modelle sind konsistenter als andere. Wenn Sie KI für Produktionsarbeit oder kundenorientierte Inhalte verwenden, ist Konsistenz wichtig. Sie möchten nicht, dass eine Antwort brillant ist und die nächste mittelmäßig.
Wenn Sie KI-Modelle bewerten, ist Konsistenz eine wichtige Metrik, die Benchmarks nicht gut erfassen.
5. Prüfen Sie auf Halluzinationen und Genauigkeit
Das ist besonders wichtig, wenn Sie KI für etwas Faktisches verwenden.
KI-Modelle erfinden manchmal selbstbewusst Dinge. Sie zitieren Studien, die nicht existieren, verweisen auf Funktionen, die Produkte nicht haben, oder geben "Fakten" an, die völlig falsch sind.
Testen Sie dies, indem Sie Fragen stellen, bei denen Sie die richtige Antwort kennen, oder indem Sie das Modell bitten, Quellen anzugeben. Dann überprüfen Sie, ob diese Quellen tatsächlich existieren und das sagen, was das Modell behauptet.
In meiner Erfahrung beim Testen von Sprachmodellen unterscheiden sie sich hier erheblich. Einige sind anfälliger für selbstbewusste Halluzinationen als andere, und Sie müssen wissen, welchen Sie für faktische Arbeit vertrauen können.
6. Dokumentieren Sie Ihre Ergebnisse
Notieren Sie, was gut funktioniert hat und was nicht. Ihr zukünftiges Ich wird Ihnen danken. Sie können die Notizen auch innerhalb von Zemith Note speichern, indem Sie zur Notizseite gehen oder einfach einen neuen Notiz-Tab innerhalb von FocusOS erneut öffnen
Ich führe eine einfache Tabelle:
- Aufgabentyp
- Welche Modelle ich getestet habe
- Gewinner und warum
- Alle bemerkenswerten Unterschiede
Nach einigen Wochen des Testens von KI-Modellen auf diese Weise entstehen Muster. Sie werden anfangen zu sehen, welches Modell konsistent für welche Art von Aufgabe gewinnt.
Worauf Sie achten sollten, wenn Sie KI-Modelle vergleichen
Wenn Sie Antworten von drei verschiedenen Modellen anstarren, ist hier, was für Ihre KI-Modell-Bewertung tatsächlich wichtig ist:
Antwortqualität: Beantwortet es tatsächlich, was Sie gefragt haben? Ist die Information genau? Ist sie vollständig oder hat sie wichtige Aspekte verpasst?
Ton und Stil: Entspricht es dem, wie Sie klingen möchten? Einige Modelle sind formeller, andere lässiger. Ich habe bemerkt, dass Claude dazu neigt, gemessener und durchdachter zu sein. ChatGPT kann dynamischer und gesprächiger sein. Ein Reddit-Benutzer sagte, ChatGPT sei "ansprechender und sympathischer" geworden, warnte aber, dass es es zu einem "sophisticated yes-man" macht, der allem zustimmt. Wenn Sie echte Kritik brauchen, müssen Sie explizit danach fragen.
Tiefe vs. Kürze: Brauchen Sie umfassende Erklärungen oder prägnante Antworten? Verschiedene Modelle standardmäßig auf unterschiedliche Detailgrade. Ich testete denselben Prompt über alle drei—ChatGPT gab mir die prägnanteste Antwort, die Sie auf einen Blick lesen konnten, Claude bot Schritt-für-Schritt-Anleitungen, und Gemini gab einen Überblick ohne Schritte.
Kreativität vs. Genauigkeit: Für kreative Aufgaben möchten Sie vielleicht unerwartete Ideen. Für analytische Arbeit wollen Sie Präzision. Modelle, die für das eine optimiert sind, haben oft Schwierigkeiten mit dem anderen.
Geschwindigkeit: Wenn Sie KI interaktiv verwenden, ist die Antwortzeit wichtig. Wenn ich KI-Modelle teste, variiert die Geschwindigkeit erheblich zwischen Modellen und sogar zwischen verschiedenen Versionen desselben Modells.
Zitiert es tatsächlich Quellen?: Das ist riesig, wenn Sie recherchieren. Gemini ist konsistent besser darin, Links zu tatsächlichen Quellen bereitzustellen. ChatGPT gibt Ihnen manchmal veraltete Informationen (es weiß nur bis Ende 2023 in der kostenlosen Version). Claude war historisch nicht großartig darin, auf Quellen zu verlinken, was frustrierend ist, wenn Sie etwas überprüfen müssen.
KI-Modellvergleich: Was ich beim Testen Tausender Prompts gelernt habe
Hier sind die Muster, die ich beim Vergleichen von KI-Modellen für verschiedene Anwendungsfälle bemerkt habe:
Für Schreiben und Content-Erstellung
ChatGPT glänzt bei kreativen, ansprechenden Inhalten. Es ist großartig für Blog-Posts, Marketing-Texte und alles, was Persönlichkeit braucht. Ein Benutzer, der Twitter-Hooks testete, sagte "keiner von ihnen ist großartig", aber Claude gab das beste Ergebnis—nicht zu wortreich, keine unnötigen Hashtags.
Claude ist besser, wenn Sie durchdachtes, nuanciertes Schreiben brauchen oder einen bestimmten Stil genau treffen möchten. Ich verwende es, um mein Schreiben zu bearbeiten, besonders wenn ich ihm zuerst Beispiele meiner besten Arbeit gebe.
Für Coding
Hier wird es interessant, wenn Sie KI-Modelle direkt gegeneinander testen.
In Tests, die ich gesehen habe, baute Claude, als er gebeten wurde, "ein vollständiges Tetris-Spiel zu erstellen", ein wunderschönes, voll funktionsfähiges Spiel mit Punkten und Steuerungen. ChatGPT erstellte etwas Grundlegendes, das funktioniert. Gemini machte es gut, war aber nicht ganz auf Claudes Niveau.
Allerdings kostet Claude Sonnet das 20-fache von Gemini Flash. Wenn Sie ein KI-Produkt bauen, bei dem Kosten wichtig sind, könnte Gemini die klügere Wahl sein. Claude produziert jedoch konsistent saubereren Code mit besserer Dokumentation für komplexe Aufgaben.
Für Recherche und Zusammenfassung
Gemini glänzt mit seinem riesigen Kontextfenster und neigt dazu, faktisch genauer zu sein. Es kann enorme Dokumente verdauen und wichtige Informationen effizient herausziehen.
Ein Rezensent, der alle drei testete, fand Gemini "den konsistentesten Allrounder" und besonders stark bei faktischen, kontextuellen Abfragen. Es hat auch tatsächliche Websuche eingebaut, anders als Claude.
Für Argumentation und Problemlösung
Die Argumentationsmodelle (wie OpenAIs o1) brechen komplexe Probleme systematisch auf. Sie sind ausgezeichnet für Planung, Strategie und mehrstufiges Denken. Aber sie sind langsamer—manchmal dauert es Minuten, bis sie antworten.
Für Analyse und Erklärungen
Claude bietet strukturierte, logische Analysen, wenn Sie KI-Modelle für diesen Zweck bewerten. Es ist besonders gut darin, komplexe Ideen aufzubrechen und sie klar zu erklären. Mehrere Reddit-Benutzer erwähnten, dass Claude großartig für "durchdachte, ausgewogene Argumente" ist, besonders bei kontroversen Themen.
Der Gedächtnisfaktor
Hier ist etwas, das mich beim Testen von Sprachmodellen überraschte—2025 hat nur ChatGPT Gedächtnis. Es erinnert sich an Details über Sie über Gespräche hinweg. Gemini und Claude nicht.
Wenn Sie eine KI brauchen, die sich an Ihre Präferenzen, Ihre Projekte, Ihren Schreibstil von Sitzung zu Sitzung erinnert, ist ChatGPT derzeit Ihre einzige Option. Ich finde das verrückt, weil es diese "magischen Momente" schafft, in denen ChatGPT Dinge basierend auf vergangenen Gesprächen vorschlägt.
ChatGPT vs Claude vs Gemini: Schneller Vergleich
| Funktion | ChatGPT | Claude | Gemini |
|---|---|---|---|
| Am besten für | Kreative Inhalte, allgemeine Aufgaben | Code, Analyse, Bearbeitung | Recherche, lange Dokumente |
| Stärken | Ansprechender Ton, Gedächtnis | Strukturiertes Denken, sauberer Code | Faktische Genauigkeit, Kontext |
| Schwächen | Kann ein "Yes-Man" sein | Kein Gedächtnis, weniger Quellen | Weniger kreativ |
| Kontextfenster | 128K Tokens | 200K Tokens | 1M Tokens |
| Websuche | Mit Plugins | Eingebaut | Eingebaut |
| Kosten | Mittel | Höchste | Niedrigste (Flash) |
| Geschwindigkeit | Schnell | Schnell | Variiert |
Aber hier ist die wichtigste Erkenntnis: Ihre Erfahrung wird variieren. Was für meine Anwendungsfälle funktioniert, funktioniert möglicherweise nicht für Ihre. Deshalb müssen Sie KI-Modelle mit Ihren eigenen Prompts testen.
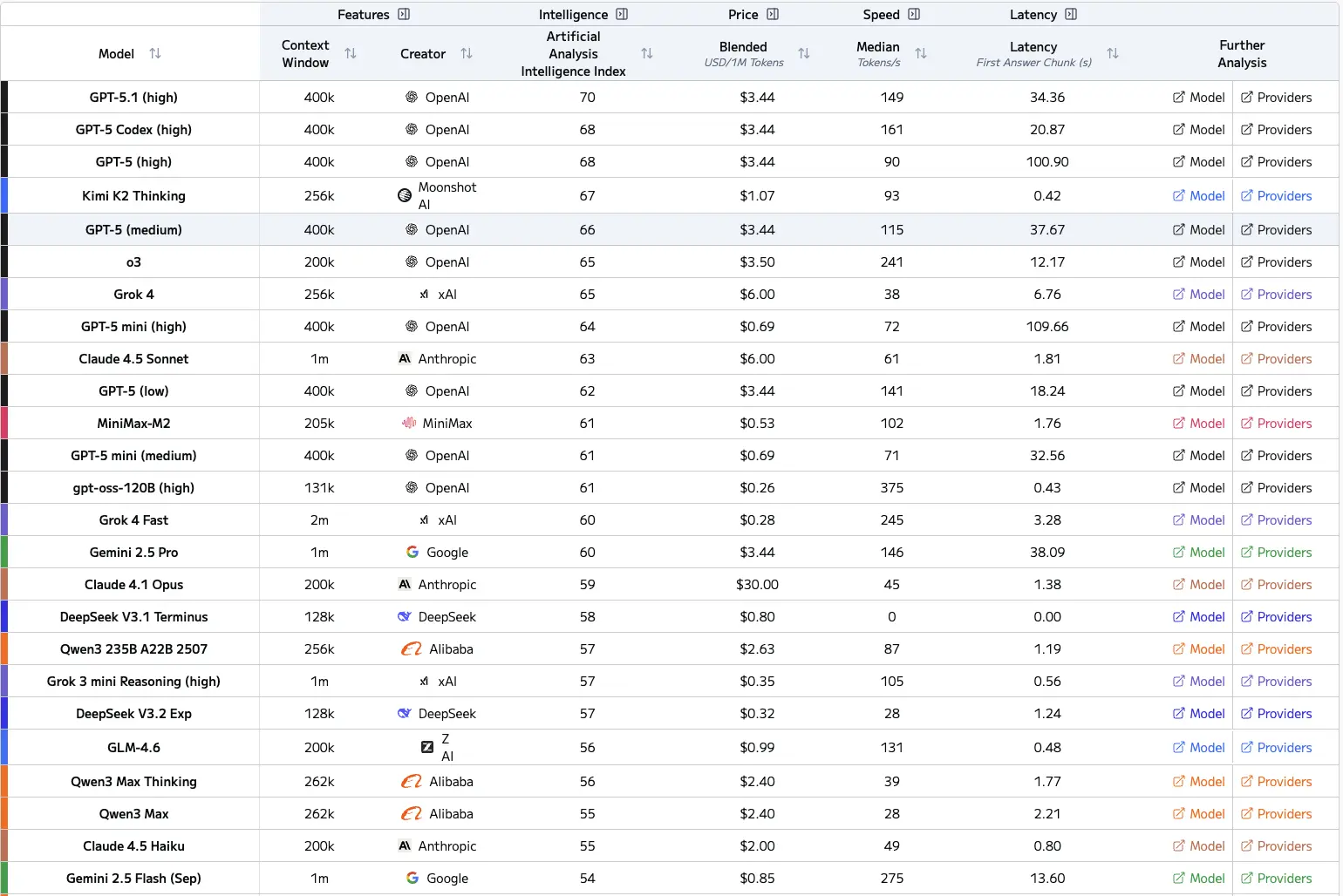
Unten ist das Diagramm der Frontier-LLM zur Referenz sowie der Intelligenzindex
Tools zum Testen von KI-Modellen
Der einfachste Weg, verschiedene KI-Modelle zu testen, ist, sie nebeneinander zu verwenden. Hier sind Ihre Optionen:
Option 1: Mehrere Tabs öffnen - Kostenlos aber nervig. Kopieren Sie Ihren Prompt in ChatGPT, Claude und Gemini in separate Tabs. Vergleichen Sie manuell.
Option 2: Verwenden Sie Zemiths Focus OS - Das habe ich speziell für dieses Problem gebaut. Verwenden Sie verschiedene Modelle innerhalb unserer FocusOS-Tabs, sehen Sie Ergebnisse nebeneinander mit unserem Chrome-ähnlichen Tab-System. Sie können schnell zwischen Modellantworten wechseln, ohne Kontext zu verlieren oder Fenster zu jonglieren. Spart Zeit und macht Vergleiche offensichtlich.
Option 3: API-Zugriff - Wenn Sie technisch versiert sind, können Sie Skripte schreiben, um KI-Modelle programmatisch zu testen. Gut für Bulk-Tests, erfordert aber Programmierkenntnisse.
Option 4: Andere Vergleichstools - Es gibt einige andere Plattformen wie Poe oder nat.dev, die Ihnen erlauben, Modelle zu vergleichen, obwohl die Funktionen variieren.
Der Schlüssel ist, eine systematische Methode zum Vergleichen von KI-Modellen zu haben, nicht nur zufällig zwischen ihnen zu springen. Zemiths Focus OS macht dies mit seiner Tab-basierten Oberfläche sehr einfach—denken Sie an Chrome-Tabs, aber jeder Tab ist eine andere KI-Modellantwort auf Ihren Prompt.
Häufige Fehler beim Testen von KI-Modellen
Ich habe alle diese Fehler gemacht. Lernen Sie aus meinem Schmerz:
Fehler 1: Mit verschiedenen Prompts testen - Sie ändern die Formulierung leicht für jedes Modell und fragen sich dann, warum die Ergebnisse unterschiedlich sind. Verwenden Sie identische Prompts.
Fehler 2: Nur einmal testen - Sie führen einen Test durch und erklären einen Gewinner. KI-Modelle haben Variabilität. Testen Sie mehrmals.
Fehler 3: Kosten ignorieren - Sie finden das "beste" Modell, aber es kostet das 20-fache. Für den Produktionseinsatz ist der Preis pro Token wichtig.
Fehler 4: Edge-Cases nicht testen - Alles funktioniert großartig mit einfachen Prompts, dann bricht Ihr echter Anwendungsfall alles. Testen Sie das seltsame Zeug.
Fehler 5: Subjektivem "Gefühl" vertrauen - Sie mögen die Persönlichkeit eines Modells, also verwenden Sie es für alles. Das ist in Ordnung für gelegentliche Nutzung, schrecklich für Geschäftsentscheidungen.
Fehler 6: Ergebnisse nicht dokumentieren - Sie testen gründlich, schreiben aber nichts auf. Drei Wochen später können Sie sich nicht erinnern, welches Modell für was besser war.
Wie lange dauert es, KI-Modelle zu testen?
Ehrlich? Etwa eine Woche echter Nutzung gibt Ihnen 80% von dem, was Sie wissen müssen.
Hier ist, was ich empfehle:
- Tag 1-2: Testen Sie Ihre Top 3-5 Aufgaben über alle Modelle. Dokumentieren Sie Gewinner.
- Tag 3-5: Verwenden Sie Ihren "Gewinner" für jeden Aufgabentyp in echter Arbeit. Notieren Sie alle Probleme.
- Tag 6-7: Testen Sie alles neu, was nicht wie erwartet funktionierte. Passen Sie Ihre Auswahl an.
Danach haben Sie ein solides Gefühl dafür, wann Sie nach welchem Modell greifen sollten. Sie werden im Laufe der Zeit weiter lernen, aber die anfängliche Investition ist nur eine Woche Aufmerksamkeit.
Der beste Weg, KI-Modelle zu testen, ist nicht, einen Monat mit formaler Bewertung zu verbringen. Es geht darum, während Ihrer normalen Arbeit für kurze Zeit absichtlich zu testen.
Der Multi-Modell-Ansatz
Das ist, was ich tatsächlich jetzt tue, und was ich empfehle, nachdem Sie KI-Modelle getestet haben:
Versuchen Sie nicht, ein "bestes" Modell zu wählen. Verwenden Sie verschiedene Modelle für verschiedene Aufgaben.
Ich verwende ChatGPT für Brainstorming und erste Entwürfe kreativer Inhalte. Ich verwende Claude, wenn ich sorgfältige Analyse oder Bearbeitung brauche. Ich verwende Gemini, wenn ich mit großen Dokumenten arbeite oder aktuelle Informationen aus dem Web brauche.
Deshalb habe ich Zemith gebaut, um mehrere Modelle zu unterstützen. Die Zukunft geht nicht darum, die eine perfekte KI zu finden—es geht darum, das richtige Werkzeug für jede Aufgabe zu haben.
Denken Sie daran wie verschiedene Apps auf Ihrem Telefon. Sie verwenden Instagram nicht für E-Mail oder Gmail für Fotos. Verschiedene Werkzeuge für verschiedene Zwecke.
Wenn Sie KI-Modelle richtig vergleichen und bewerten, erkennen Sie, dass Spezialisierung Generalisierung schlägt.
Praktische Tipps zum effektiven Testen von KI-Modellen
Klein anfangen: Versuchen Sie nicht, alles auf einmal zu testen. Wählen Sie drei häufige Aufgaben und testen Sie diese zuerst gründlich.
Seien Sie spezifisch: Vage Prompts geben vage Ergebnisse. Testen Sie mit den tatsächlichen, spezifischen Prompts, die Sie in echter Arbeit verwenden werden.
Edge-Cases testen: Testen Sie nicht nur den Happy Path. Versuchen Sie Prompts, die mehrdeutig, komplex oder ungewöhnlich sind. Dort sehen Sie echte Unterschiede in der KI-Modellleistung.
Kosten berücksichtigen: Einige Modelle sind teurer als andere. Wenn Sie Hochvolumenarbeit machen, berücksichtigen Sie die Preise, wenn Sie KI-Modelle bewerten. Ein etwas schlechteres Modell, das 10x weniger kostet, könnte die bessere Wahl sein.
Ihre Prompts iterieren: Manchmal ist das, was wie eine Modellschwäche aussieht, tatsächlich ein Prompt-Problem. Wenn die Ergebnisse bei keinem Modell gut sind, überarbeiten Sie Ihren Prompt.
Aktuell bleiben: Modelle verbessern sich ständig. Was heute wahr ist, könnte sich nächsten Monat ändern. Testen Sie wichtige Anwendungsfälle regelmäßig neu. Der beste Weg, KI-Modelle zu testen, umfasst regelmäßige Neubewertung.
Ihre Erkenntnisse teilen: Treten Sie Gemeinschaften bei, in denen Menschen über das Testen von Sprachmodellen diskutieren. Sie werden aus den Erfahrungen anderer lernen und Anwendungsfälle entdecken, die Sie nicht berücksichtigt hatten.
FAQ: KI-Modelle testen
Brauche ich technische Fähigkeiten, um KI-Modelle zu testen?
Nein. Wenn Sie Text kopieren und einfügen können, können Sie KI-Modelle testen. Der von mir beschriebene Ansatz erfordert keine Programmier- oder technischen Kenntnisse.
Was ist der beste kostenlose Weg, KI-Modelle zu testen?
Öffnen Sie kostenlose Konten für ChatGPT, Claude und Gemini. Verwenden Sie mehrere Tabs. Es ist umständlich, funktioniert aber. Die meisten Modelle haben kostenlose Stufen, die für Tests ausreichen.
Wie oft sollte ich KI-Modelle testen?
Führen Sie eine gründliche Bewertung durch, wenn Sie zum ersten Mal KI für die Arbeit verwenden. Dann testen Sie alle 3-4 Monate neu, wenn sich Modelle verbessern. Testen Sie auch, wenn neue Hauptmodelle erscheinen.
Kann ich KI-Modell-Benchmarks überhaupt vertrauen?
Sie sind nicht nutzlos, nur begrenzt. Benchmarks sagen Ihnen theoretische Fähigkeiten. Ihr Testen sagt Ihnen praktische Leistung für Ihre spezifischen Bedürfnisse. Verwenden Sie beides.
Sollte ich KI-Modelle für jede einzelne Aufgabe testen?
Nein. Testen Sie Ihre häufigsten Aufgaben und Ihre wichtigsten Aufgaben. Sie werden schnell ein Gefühl dafür entwickeln, welches Modell Sie für Variationen verwenden sollten.
Was, wenn das "beste" Modell zu teuer ist?
Dann ist es tatsächlich nicht das beste Modell für Sie. Das beste Modell ist das, das Ihnen ausreichend gute Ergebnisse zu einem Preis gibt, der für Ihren Anwendungsfall Sinn macht.
Das Fazit zum Testen von KI-Modellen
Das Testen von KI-Modellen muss nicht kompliziert sein. Sie brauchen kein technisches Fachwissen oder ausgefallene Bewertungsframeworks.
Sie müssen nur die Modelle mit Ihren tatsächlichen Aufgaben verwenden, die Ergebnisse nebeneinander vergleichen und darauf achten, was funktioniert.
Ich sah jemanden auf Reddit seinen Testprozess perfekt beschreiben: "Ich springe zwischen KI-Tools wie ein koffeingetriebener Flipper. Eine Minute bitte ich Claude, einen Absatz umzuschreiben, die nächste Minute debugge ich mit ChatGPT, dann gebe ich ein PDF an Gemini weiter." So verwenden die meisten von uns diese Tools—pragmatisch, basierend auf dem, was wir gerade brauchen, wechselnd.
Die KI, die Ihnen die besten Ergebnisse für Ihre spezifischen Bedürfnisse gibt—das ist Ihre Antwort. Nicht die mit dem höchsten Benchmark-Score. Nicht die, über die alle reden. Die, die tatsächlich für Sie liefert.
Wenn Sie KI-Modelle richtig testen und vergleichen, hören Sie auf, sich auf Hype zu verlassen, und beginnen, sich auf Daten aus Ihrer eigenen Erfahrung zu verlassen.
Deshalb habe ich Zemith gebaut. Weil die Auswahl von KI-Modellen auf echtem Testen mit echten Aufgaben basieren sollte, nicht auf Marketingversprechen oder theoretischen Benchmarks.
Versuchen Sie mehrere Modelle. Vergleichen Sie sie direkt. Finden Sie, was funktioniert. So einfach ist das.
Und ehrlich? Sie könnten feststellen, dass die Verwendung mehrerer Modelle—jedes für das, was es am besten kann—besser ist, als zu versuchen, ein Modell zu zwingen, alles zu tun.
Das war jedenfalls meine Erfahrung. Und ich wette, es wird auch Ihre sein, sobald Sie anfangen, selbst zu testen.
Möchten Sie KI-Modelle auf einfache Weise testen? Schauen Sie sich Zemith an, wo Sie ChatGPT, Claude, Gemini und mehr nebeneinander mit unserer Focus OS-Oberfläche verwenden können. Die All-in-One-KI-App, mit der Sie in Sekunden zwischen Modellantworten wechseln können, mit nur einem Abonnementplan
Zemith Funktionen entdecken
Jede Top-KI. Ein Abo.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ mehr












Immer aktiv, Echtzeit-KI.
Sprache + Bildschirmfreigabe · sofortige Antworten
Wie lernt man am besten eine neue Sprache?
Immersion und verteilte Wiederholung funktionieren am besten. Versuchen Sie, täglich Medien in Ihrer Zielsprache zu konsumieren.
Sprache + Bildschirmfreigabe · KI antwortet in Echtzeit
Bildgenerierung
Flux, Nano Banana, Ideogram, Recraft + mehr

Schreibe in Gedankengeschwindigkeit.
KI-Autovervollständigung, Umschreiben & Erweitern auf Befehl
Jedes Dokument. Jedes Format.
PDF, URL oder YouTube → Chat, Quiz, Podcast & mehr
Videoerstellung
Veo, Kling, MiniMax, Sora + mehr

Text-zu-Sprache
Natürliche KI-Stimmen, 30+ Sprachen
Code-Generierung
Schreiben, debuggen & Code erklären
Chat mit Dokumenten
PDFs hochladen, Inhalte analysieren
Deine KI in der Tasche.
Voller Zugang auf iOS & Android · überall synchronisiert
Deine unendliche KI-Leinwand.
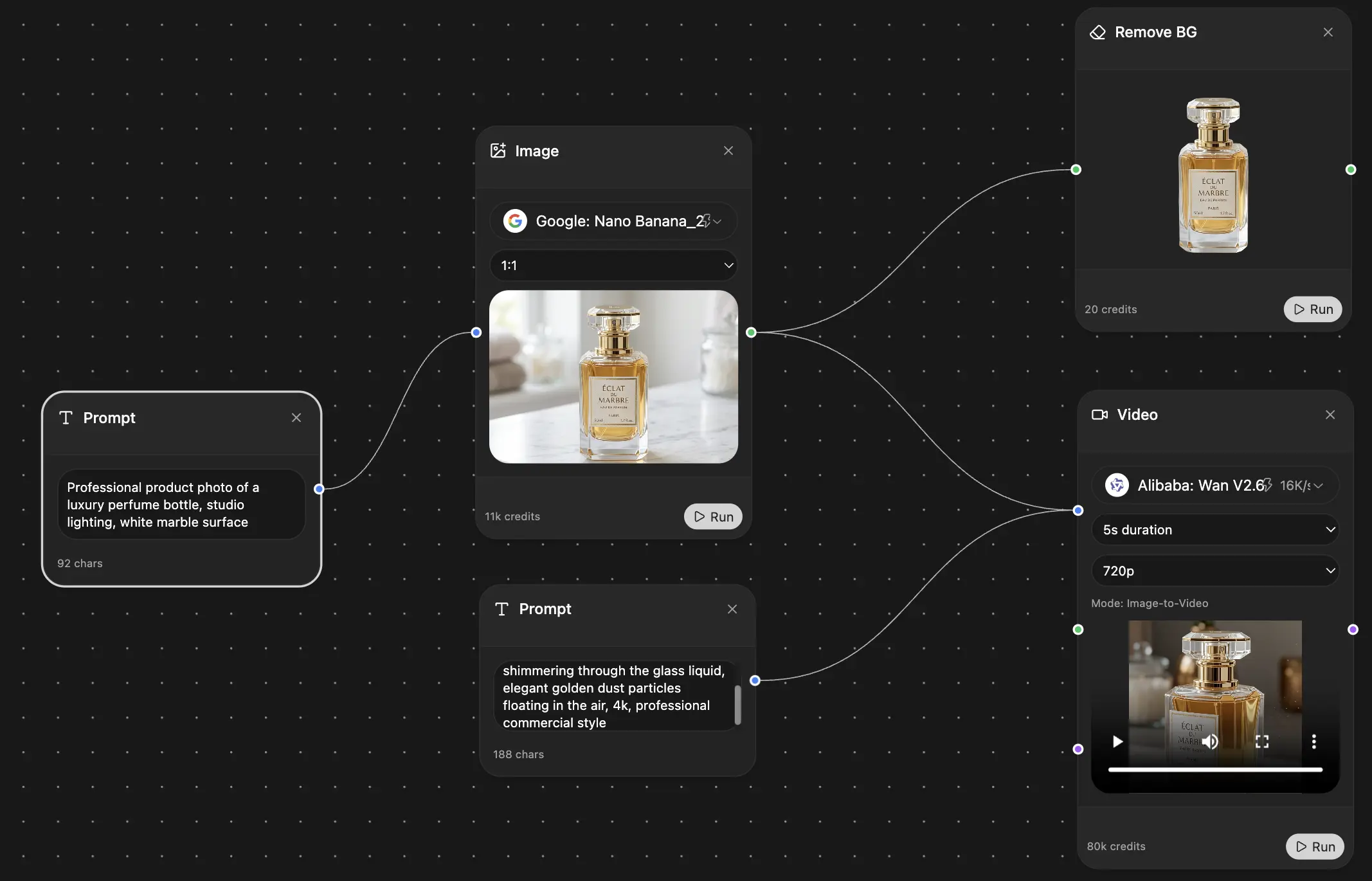
Chat, Bild, Video & Motion-Tools — nebeneinander
Sparen Sie Stunden an Arbeit und Forschung
Einfache, erschwingliche Preise
Vertraut von Teams bei
Kostenlos
Keine Kreditkarte erforderlich
- 100 Credits täglich
- 3 KI-Modelle zum Ausprobieren
- Einfacher KI-Chat
Plus
- 1.000.000 Credits/Monat
- 25+ KI-Modelle — GPT, Claude, Gemini, Grok & mehr
- Agent Mode mit Websuche, Computer-Tools und mehr
- Creative Studio: Bildgenerierung und Videogenerierung
- Project Library: Chat mit Dokumenten, Webseiten und YouTube, Podcast-Erstellung, Lernkarten, Berichte und mehr
- Workflow Studio und FocusOS
Professional
- Alles in Plus, plus:
- 2.100.000 Credits/Monat
- Pro-exklusive Modelle (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- Erster Zugang zu den neuesten Funktionen
- Zugang zu zusätzlichen Angeboten