
AIモデルのテスト方法:必要な唯一のガイド(2025)
6ステップのフレームワークを使用して、ChatGPT、Claude、GeminiなどのAIモデルをテストする方法を学びましょう。実際のタスクを使用してAIモデルを並べて比較—技術スキルは不要です。
AIモデルのテスト方法:実際に必要な唯一のガイド
約1年前、Zemithを構築していたときに、AIモデルのテストに夢中になりました。ML研究者だからではありません—そうではありません。誇大広告に騙され続けたからです。
誰もがGPT-4が最高だと言いました。その後、Claudeが登場し、人々はそれが最高だと言いました。次にGemini。その後、新しいモデルが登場すると、突然それが王様になりました。ゴールポストは常に動き続け、私は気づきました:どのAIモデルが実際にあなたのニーズに合うかを知りたいなら、AIモデルを自分でテストする必要があります。
ベンチマークを読むのではありません。マーケティングの主張を信じるのではありません。実際にテストするのです。
これは困惑度スコアやBLEUメトリクスに関する技術ガイドではありません。これは実際の人々—創設者、クリエイター、開発者、AIを日常的に使用している人々—がAIモデルを評価し、どれが実際に機能するかを理解する方法です。
一部の人々は比較のためにチャートを見ることを好みますが、実際の世界の結果は大きく異なることがよくあります。モデルの応答が何でどのようにあるかを確実に知る唯一の方法は、実際の使用テストを通じてです。
自分でAIモデルをテストすることが不可欠な理由
これは苦労して学んだことです:AIモデルのベンチマークは、実際の作業には基本的に役に立ちません。
モデルが学術テストで優位に立つかもしれませんが、それがあなたの声でメールを書くか、あなたの業界の専門用語を理解するか、あなたのビジネスが毎日扱う奇妙なエッジケースを処理するかは教えてくれません。
数ヶ月間、RedditのAIモデルに関する議論を読んでいますが、繰り返し現れるテーマがあります:誰かが「どのAIを使うべきか?」と尋ねると、回答はバラバラです。ある人はClaudeがコーディングで無敵だと断言します。別の人はChatGPTがより創造的だと言います。他の誰かはGeminiが最も正確だと主張します。彼らは皆正しく、皆間違っています。
これらのモデルを数千回テストした後、真実はこれです:単一の「最高の」AIモデルは存在しません。それぞれに異なる強みがあり、それらの強みは実際に何をしようとしているかによって異なります。
ChatGPTは創造的で魅力的なコンテンツを提供するかもしれません。Claudeは分析に最適な構造化された、思慮深い応答を提供するかもしれません。Geminiは事実研究に優れ、長いドキュメント用の巨大なコンテキストウィンドウを持っています。
どのモデルがあなたに最適かを知る唯一の方法は、実際のユースケースでAIモデルをテストすることです。仮説的なものではありません。汎用的なプロンプトではありません。あなたの実際の作業です。
誰もが実際に尋ねている質問
AIモデルのテスト方法に入る前に、RedditやDMで常に見る質問に対処させてください:
「すべてにChatGPTを使えばいいのでは?」
できますが、多くの機会を逃すことになります。時には適切なドライバーが必要なのに、スイスアーミーナイフを使うようなものです。
「ベンチマークでは不十分なの?」
あまりそうではありません。Claudeがベンチマークでスコアが低かったが、コードの説明がはるかに優れていたと指摘したRedditスレッドを見ました。ベンチマークは研究者が重要だと思うことを測定しますが、実際に作業を完了するのに役立つものではありません。
「ある応答が別の応答より優れているかどうかをどうやって知るの?」
これが本当の質問で、正直に言うと、思っているより簡単です。答えを使ってタスクをより良く、より速く、またはより少ないイライラで達成できるなら—それがあなたの答えです。
「これは考えすぎではないの?」
おそらく、カジュアルにAIを使っているなら。しかし、ビジネスを構築している、毎日コンテンツを書いている、または実際の作業にAIに依存しているなら?テストは考えすぎではありません—それはデューデリジェンスです。
AIモデルのテスト方法:6ステップフレームワーク
技術メトリクスは忘れましょう。言語モデルを実際にテストし、意味のある方法でAIモデルを比較する方法は次のとおりです:
1. 実際のタスクから始める
「猫についての物語を書く」のような汎用的なプロンプトでAIモデルをテストしないでください。それは役に立ちません。
代わりに、実際に定期的に行う3〜5つのタスクを選びます:
- よく送る特定のタイプのメールを起草する
- 仕事から典型的なドキュメントを要約する
- 実際のプロジェクトのアイデアを生成する
- 実際に構築しているもののコードを書く
- 受け取ったカスタマーサポートの質問に答える
これらのタスクがより具体的で現実的であるほど、AIモデルの評価は良くなります。
2. 異なるAIモデル間で同一のプロンプトを使用する
AIモデルをテストする際、これは重要です。まったく同じプロンプトを取り、ChatGPT、Claude、Gemini、および検討している他のモデルで実行します。
言葉を変えないでください。各モデルに合わせて調整しないでください。出力を公平に比較できるように、同一の入力を使用します。
Zemithでこれを初めて行ったとき、ショックを受けました。創造的なブレインストーミングでは、ChatGPTは一貫してより興味深い角度を提供しました。データの分析や複雑なトピックの分解では、Claudeはより明確で整理されていました。現在の情報での事実研究では、Geminiが先行しました。
誰かが同じなぞなぞで3つのモデルすべてをテストした素晴らしいReddit投稿を見ました:「医者の息子の父親が医者でないことがどうして可能か?」3つすべてが正解しましたが、アプローチは完全に異なりました。Claudeは最も詳細な分解を提供し、問題の考え方における潜在的な偏見さえ指摘しました。ChatGPTは簡潔で要点を突いていました。Geminiは正しい答えを簡潔な説明とともに提供しました。
すべて正しく、すべて有用ですが、それぞれ異なるスタイルがあります。実際の作業にどれを使用するかを決定する際、この違いは重要です。
3. 記憶からではなく、並べて比較する
人間の記憶は比較に不向きです。今日ChatGPTをテストし、明日Claudeをテストすると、それぞれが何と言ったかのニュアンスを忘れてしまいます。
これがまさにZemithでFocusOSを構築した理由です。複数のタブ間でどのモデルが何と言ったかを覚えようとするのは悪夢だからです。
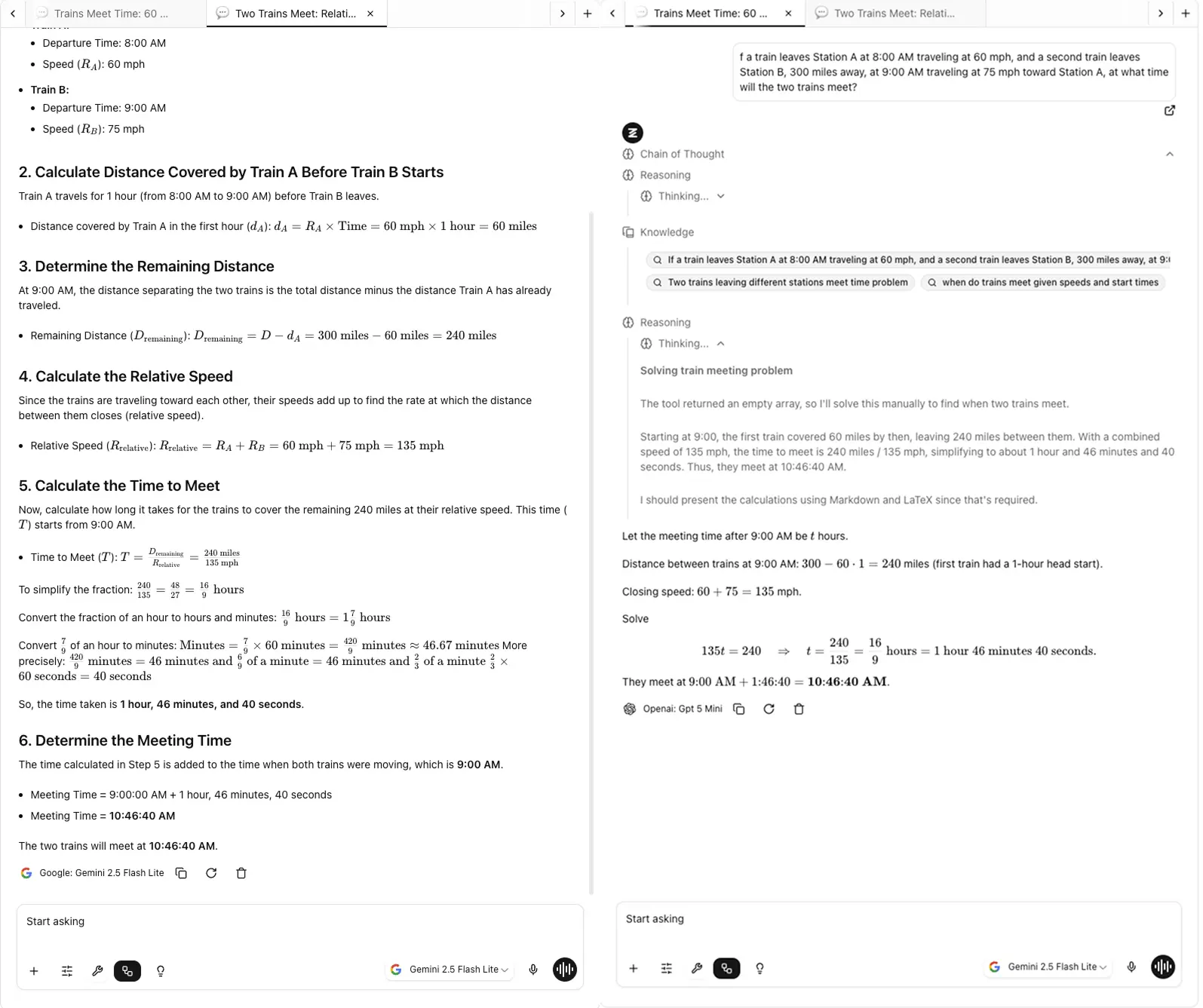
Zemithでは、ChromeのようなタブシステムでFocus OSを設計しました。これにより、ブラウザタブを操作することなく、1つのページからコンテキストを失うことなく、タブをすばやく切り替えることができます。どの答えがどのモデルから来たかを追跡しなくて済みます。
応答を一緒に見ると、そうでなければ見逃すパターンが明らかになります:
- どのモデルが実際に質問に答えているかvs.どのモデルが冗長か?
- どのモデルが好みのトーンを維持しているか?
- どのモデルが実際に使用できる情報を提供しているか?
これはAIモデルをテストする最良の方法です。リアルタイムで違いを見ているので、記憶から再構築しようとしていません。
4. 一貫性とAIモデルのパフォーマンスをテストする
各モデルで同じプロンプトを数回実行します。AIモデルは確率的です—常に同じ答えを出すわけではありません。
一部のモデルは他のモデルより一貫しています。AIを本番作業や顧客向けコンテンツに使用している場合、一貫性が重要です。1つの応答が素晴らしく、次の応答が平凡であることは望ましくありません。
AIモデルを評価する際、一貫性はベンチマークがうまく捉えられない重要なメトリクスです。
5. 幻覚と正確性をチェックする
事実に関する何かにAIを使用している場合、これは特に重要です。
AIモデルは時々自信を持って物事を作り上げます。存在しない研究を引用し、製品が持っていない機能を参照し、完全に間違った「事実」を述べます。
正しい答えを知っている質問を尋ねるか、モデルにソースを引用するよう依頼してこれをテストします。次に、それらのソースが実際に存在し、モデルが主張することを言っていることを確認します。
言語モデルをテストした経験では、これらは大きく異なります。一部は他のモデルよりも自信のある幻覚を起こしやすく、事実作業に信頼できるものを知る必要があります。
6. 結果を文書化する
何がうまくいき、何がうまくいかなかったかを記録してください。将来の自分が感謝します。Zemithノート内にノートを保存することもできます。ノートページに移動するか、FocusOS内で新しいノートタブを再度開くだけです
シンプルなスプレッドシートを保持しています:
- タスクタイプ
- テストしたモデル
- 勝者とその理由
- 注目すべき違い
この方法でAIモデルを数週間テストすると、パターンが現れます。どのモデルがどのタイプのタスクで一貫して勝つかを見始めます。
AIモデルを比較する際に探すべきもの
3つの異なるモデルからの応答を見つめているとき、AIモデルの評価に実際に重要なのは次のとおりです:
応答品質:実際に尋ねたことに答えているか?情報は正確か?完全か、それとも重要な側面を見逃しているか?
トーンとスタイル:望む音に合っているか?一部のモデルはより形式的で、他のモデルはよりカジュアルです。Claudeはより慎重で思慮深い傾向があることに気づきました。ChatGPTはより動的で会話的です。あるRedditユーザーは、ChatGPTが「より魅力的で好ましい」になったが、それがすべてに同意する「洗練されたイエスマン」になると警告しました。本当の批判が必要な場合は、明示的に要求する必要があります。
深度vs.簡潔さ:包括的な説明が必要か、簡潔な答えが必要か?異なるモデルは異なる詳細レベルにデフォルト設定されています。3つすべてで同じプロンプトをテストしました—ChatGPTは一目で読める最も簡潔な答えを提供し、Claudeはステップバイステップの指示を提供し、Geminiはステップなしの概要を提供しました。
創造性vs.正確性:創造的なタスクでは、予期しないアイデアが必要かもしれません。分析作業では、精度が必要です。1つに最適化されたモデルは、しばしばもう1つで苦労します。
速度:インタラクティブにAIを使用している場合、応答時間が重要です。AIモデルをテストする際、速度はモデル間、さらには同じモデルの異なるバージョン間で大きく異なります。
実際にソースを引用するか?:研究を行っている場合、これは重要です。Geminiは実際のソースへのリンクを提供する点で一貫して優れています。ChatGPTは時々古い情報を提供します(無料版は2023年後半までしか知りません)。Claudeは歴史的にソースへのリンクが得意ではありませんでした。何かを検証する必要がある場合、これはイライラします。
AIモデルの比較:数千のプロンプトをテストして学んだこと
異なるユースケースでAIモデルを比較する際に気づいたパターンは次のとおりです:
ライティングとコンテンツ作成の場合
ChatGPTは創造的で魅力的なコンテンツに優れています。ブログ投稿、マーケティングコピー、個性が必要なものに最適です。Twitterフックをテストしたユーザーは「どれも素晴らしくない」と言いましたが、Claudeが最高の結果を提供しました—冗長すぎず、不要なハッシュタグもありません。
Claudeは、思慮深く、ニュアンスのあるライティングが必要な場合、または特定のスタイルに密接に一致させたい場合に優れています。特に最初に最高の作品の例を提供する場合、ライティングの編集に使用します。
コーディングの場合
AIモデルを直接対決でテストする際、ここで物事が興味深くなります。
見たテストでは、「完全機能のテトリスゲームを作成する」ように求められたとき、Claudeはスコアとコントロールを備えた美しく、完全に機能するゲームを構築しました。ChatGPTは動作する基本的なものを作成しました。Geminiはうまくいきましたが、Claudeのレベルには達していませんでした。
ただし、Claude SonnetのコストはGemini Flashの20倍です。コストが重要なAI製品を構築している場合、Geminiがより賢明な選択かもしれません。Claudeは複雑なタスクで一貫してよりクリーンなコードとより良いドキュメントを生成します。
研究と要約の場合
Geminiは巨大なコンテキストウィンドウで輝き、事実的に正確な傾向があります。巨大なドキュメントを消化し、効率的に重要な情報を引き出すことができます。
3つすべてをテストしたレビュアーは、Geminiを「最も一貫したオールラウンダー」とし、特に事実的で文脈的なクエリに強いとしました。Claudeとは異なり、実際のWeb検索も組み込まれています。
推論と問題解決の場合
推論モデル(OpenAIのo1など)は複雑な問題を体系的に分解します。計画、戦略、多段階思考に優れています。ただし、より遅いです—応答に数分かかることがあります。
分析と説明の場合
この目的でAIモデルを評価する際、Claudeは構造化された論理的分析を提供します。複雑なアイデアを分解し、それらを明確に説明するのに特に優れています。複数のRedditユーザーが、Claudeは特に論争の多いトピックで「思慮深く、バランスの取れた議論」に優れていると述べました。
メモリ要因
言語モデルをテストする際に驚いたこと—2025年では、ChatGPTだけがメモリを持っています。会話を超えてあなたについての詳細を覚えています。GeminiとClaudeは持っていません。
セッションからセッションへ、あなたの好み、プロジェクト、ライティングスタイルを覚えるAIが必要な場合、ChatGPTが現在唯一の選択肢です。これは驚きです。過去の会話に基づいてChatGPTが提案する「魔法のような瞬間」を作り出すからです。
ChatGPT vs Claude vs Gemini:クイック比較
| 機能 | ChatGPT | Claude | Gemini |
|---|---|---|---|
| 最適 | 創造的コンテンツ、一般的なタスク | コード、分析、編集 | 研究、長いドキュメント |
| 強み | 魅力的なトーン、メモリ | 構造化思考、クリーンコード | 事実の正確性、コンテキスト |
| 弱点 | 「イエスマン」になる可能性 | メモリなし、ソースが少ない | 創造性が低い |
| コンテキストウィンドウ | 128Kトークン | 200Kトークン | 1Mトークン |
| Web検索 | プラグインで | 組み込み | 組み込み |
| コスト | 中 | 最高 | 最低(Flash) |
| 速度 | 速い | 速い | 変動 |
しかし、最も重要な洞察はこれです:あなたの結果は異なります。私のユースケースに機能するものがあなたには機能しないかもしれません。それが、独自のプロンプトでAIモデルをテストする必要がある理由です。
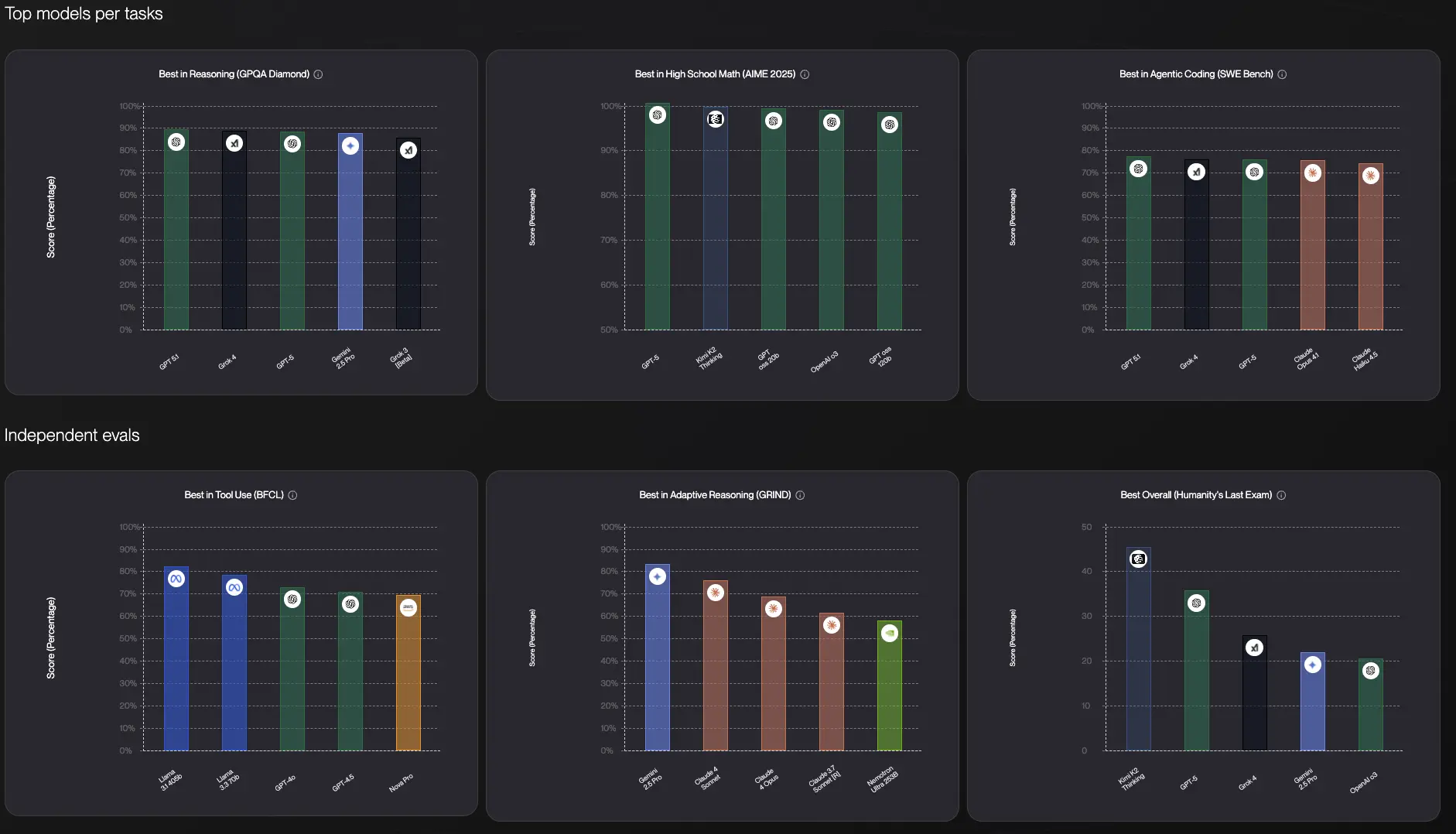
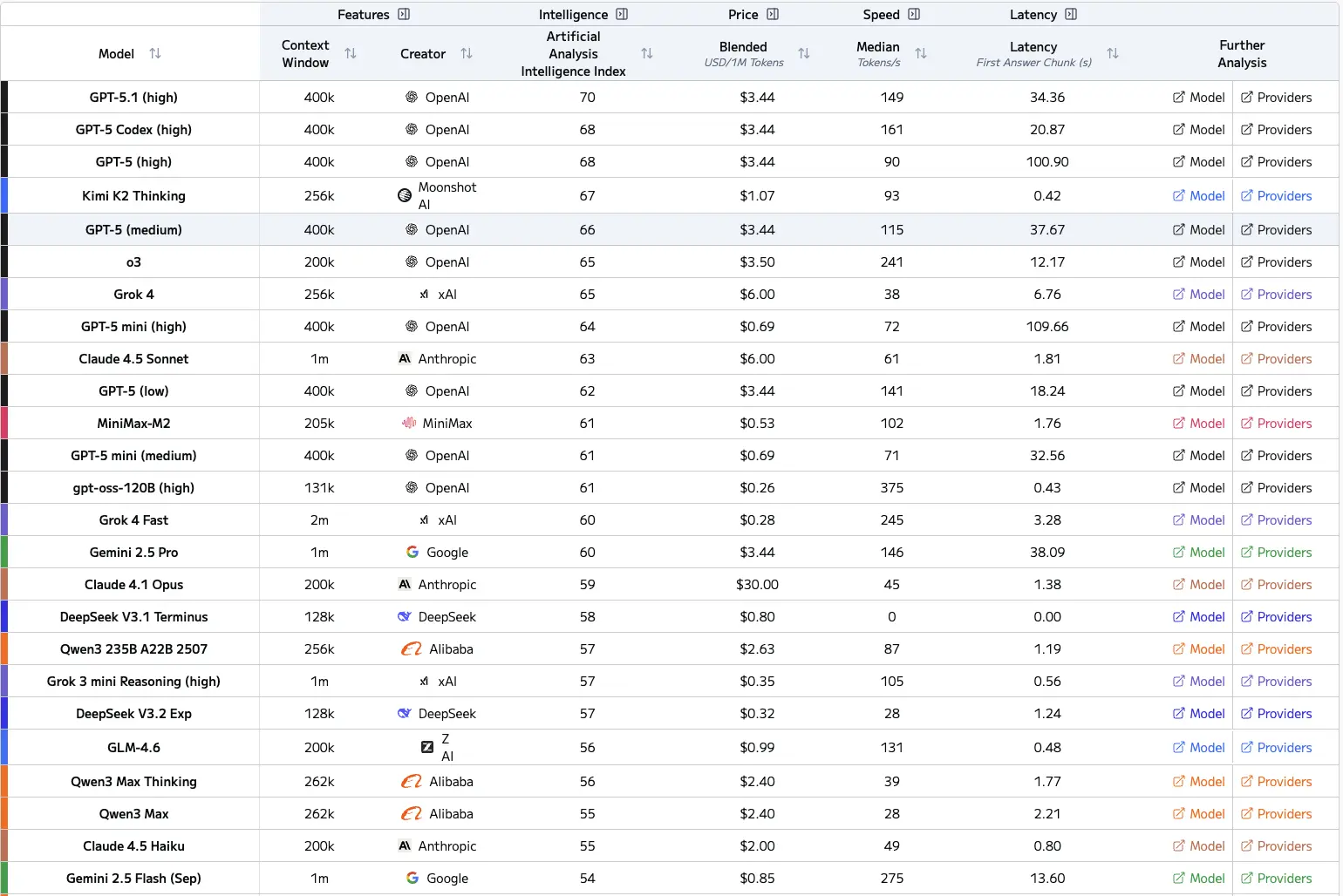
以下は、参考のためのフロンティアLLMのチャートで、インテリジェンスインデックスも含まれています
AIモデルをテストするツール
異なるAIモデルをテストする最も簡単な方法は、それらを並べて使用することです。オプションは次のとおりです:
オプション1:複数のタブを開く - 無料ですが煩わしいです。プロンプトをChatGPT、Claude、Geminiの別々のタブにコピー&ペーストします。手動で比較します。
オプション2:ZemithのFocus OSを使用 - これがこの問題を解決するために特別に構築したものです。FocusOSタブ内で異なるモデルを使用し、Chromeのようなタブシステムで結果を並べて表示します。コンテキストを失ったり、ウィンドウを操作したりすることなく、モデルの応答間をすばやく切り替えることができます。時間を節約し、比較を明確にします。
オプション3:APIアクセス - 技術的な場合、スクリプトを書いてAIモデルをプログラムでテストできます。バルクテストに適していますが、コーディング知識が必要です。
オプション4:その他の比較ツール - Poeやnat.devなど、モデルを比較できる他のプラットフォームがいくつかありますが、機能は異なります。
重要なのは、AIモデルをランダムに切り替えるのではなく、体系的に比較する方法を持つことです。ZemithのFocus OSは、タブベースのインターフェースでこれを非常に簡単にします—Chromeタブを考えてください。ただし、各タブはプロンプトに対する異なるAIモデルの応答です。
AIモデルをテストする際の一般的な間違い
これらすべての間違いを犯しました。私の苦痛から学んでください:
間違い1:異なるプロンプトでテストする - 各モデルで言葉を少し変えてから、なぜ結果が異なるのか不思議に思います。同一のプロンプトを使用してください。
間違い2:1回だけテストする - 1回のテストを実行して勝者を宣言します。AIモデルには変動性があります。複数回テストしてください。
間違い3:コストを無視する - 「最高の」モデルを見つけますが、コストが20倍です。本番使用では、トークンあたりのコストが重要です。
間違い4:エッジケースをテストしない - シンプルなプロンプトではすべてが完璧に機能し、実際のユースケースですべてが壊れます。奇妙なものをテストしてください。
間違い5:主観的な「感じ」を信頼する - 1つのモデルの個性が好きなので、すべてにそれを使用します。カジュアルな使用には問題ありませんが、ビジネス決定には最悪です。
間違い6:結果を文書化しない - 徹底的にテストしますが、何も書き留めません。3週間後、どのモデルが何に優れていたか覚えていません。
AIモデルのテストにどのくらい時間がかかりますか?
正直に?約1週間の実際の使用で、必要な情報の80%が得られます。
推奨事項は次のとおりです:
- 1-2日目:すべてのモデルで上位3-5のタスクをテストします。勝者を文書化します。
- 3-5日目:各タスクタイプの「勝者」を実際の作業で使用します。問題を記録します。
- 6-7日目:期待どおりに機能しなかったものを再テストします。選択を調整します。
その後、いつどのモデルに手を伸ばすべきかについての確かな感覚が得られます。時間の経過とともに学習を続けますが、初期投資は1週間の注意を払うだけです。
AIモデルをテストする最良の方法は、正式な評価に1ヶ月を費やすことではありません。通常の作業中に短い期間、意図的にテストすることです。
マルチモデルアプローチ
これが私が実際に今行っていること、そしてAIモデルをテストした後に推奨することです:
1つの「最高の」モデルを選ぼうとしないでください。異なるタスクに異なるモデルを使用します。
ChatGPTをブレインストーミングと創造的コンテンツの最初のドラフトに使用します。注意深い分析や編集が必要な場合はClaudeを使用します。大きなドキュメントを扱う場合や、Webから最新の情報が必要な場合はGeminiを使用します。
これが、Zemithを複数のモデルをサポートするように構築した理由です。未来は完璧なAIを見つけることではありません—各仕事に適切なツールを持つことです。
スマートフォンに異なるアプリがあるようなものと考えてください。Instagramでメールを送信したり、Gmailで写真を撮ったりしません。目的ごとに異なるツールです。
AIモデルを適切に比較し評価すると、専門化が一般化に勝つことがわかります。
AIモデルを効果的にテストする実用的なヒント
小さく始める:一度にすべてをテストしようとしないでください。3つの一般的なタスクを選び、最初にそれらを徹底的にテストします。
具体的にする:曖昧なプロンプトは曖昧な結果を生みます。実際の作業で使用する実際の、具体的なプロンプトでテストします。
エッジケースをテストする:ハッピーパスだけをテストしないでください。曖昧、複雑、または異常なプロンプトを試してください。そこがAIモデルのパフォーマンスの真の違いが見られる場所です。
コストを考慮する:一部のモデルは他のモデルより高価です。高量の作業を行っている場合、AIモデルを評価する際に価格を考慮してください。10倍安いわずかに劣るモデルがより良い選択かもしれません。
プロンプトを反復する:モデルの弱点のように見えるものが実際にはプロンプトの問題であることがあります。どのモデルでも結果が良くない場合、プロンプトを修正してください。
最新の状態を保つ:モデルは絶えず改善しています。今日真実であることは、来月変わるかもしれません。重要なユースケースで定期的に再テストします。AIモデルをテストする最良の方法には、定期的な再評価が含まれます。
発見を共有する:言語モデルのテストについて議論するコミュニティに参加してください。他の人の経験から学び、考慮していなかったユースケースを発見します。
よくある質問:AIモデルのテスト
AIモデルをテストするために技術スキルが必要ですか?
いいえ。テキストをコピー&ペーストできれば、AIモデルをテストできます。概説したアプローチには、コーディングや技術知識は不要です。
AIモデルをテストする最良の無料方法は何ですか?
ChatGPT、Claude、Geminiの無料アカウントを開きます。複数のタブを使用します。不格好ですが機能します。ほとんどのモデルには、テストに十分な無料ティアがあります。
どのくらいの頻度でAIモデルをテストすべきですか?
作業にAIを使用し始めたときに徹底的な評価を行います。その後、モデルが改善するにつれて3-4ヶ月ごとに再テストします。新しい主要モデルが発売されたときもテストします。
AIモデルのベンチマークを信頼できますか?
無用ではありませんが、限定的です。ベンチマークは理論的な能力を教えてくれます。あなたのテストは、特定のニーズに対する実際のパフォーマンスを教えてくれます。両方を使用してください。
すべてのタスクでAIモデルをテストすべきですか?
いいえ。最も一般的なタスクと最も重要なタスクをテストしてください。バリエーションにどのモデルを使用するかについて、すぐに直感を開発します。
「最高の」モデルが高すぎる場合はどうすればよいですか?
それなら、それは実際にはあなたにとって最高のモデルではありません。最高のモデルは、あなたのユースケースに意味のある価格で十分に良い結果を提供するモデルです。
AIモデルのテスト方法に関する結論
AIモデルのテストは複雑である必要はありません。技術的専門知識や派手な評価フレームワークは必要ありません。
実際のタスクでモデルを使用し、結果を並べて比較し、何が機能するかに注意を払うだけです。
Redditで誰かがテストプロセスを完璧に説明しているのを見ました:「カフェインで動くピンボールのようにAIツールの間を跳ね回っています。1分でClaudeに段落を書き直すように依頼し、次の分でChatGPTでデバッグし、次にPDFをGeminiに渡します。」これが私たちのほとんどがこれらのツールを使用する方法です—実用的に、その時必要なものに基づいて切り替えます。
特定のニーズに最良の結果を提供するAI—それがあなたの答えです。最高のベンチマークスコアを持つものではありません。誰もが話しているものではありません。実際にあなたのために機能するものです。
AIモデルを適切にテストし比較すると、誇大広告に依存するのをやめ、自分の経験からのデータに依存し始めます。
これがZemithを構築した理由です。AIモデルの選択は、マーケティングの主張や理論的なベンチマークではなく、実際のタスクでの実際のテストに基づくべきだからです。
複数のモデルを試してください。直接比較してください。機能するものを見つけてください。それだけです。
そして正直に言うと?複数のモデルを使用すること—それぞれが最善を尽くす—が、1つのモデルにすべてを強制しようとするよりも優れていることがわかるかもしれません。
とにかく、これが私の経験です。自分でテストを始めれば、あなたの経験にもなるだろうと賭けています。
簡単な方法でAIモデルをテストしたいですか?Zemithをチェックしてください。Focus OSインターフェースでChatGPT、Claude、Geminiなどを並べて使用できます。1つのサブスクリプションプランのみで、数秒でモデルの応答を切り替えることができるオールインワンAIアプリ
Zemithの機能を探索
すべてのトップAI。1つのサブスク。
ChatGPT、Claude、Gemini、DeepSeek、Grok & 25+モデル












常時オン、リアルタイムAI。
音声 + 画面共有 · 即座に回答
新しい言語を学ぶ最良の方法は何ですか?
没入学習と間隔反復が最も効果的です。毎日ターゲット言語のメディアを消費してみてください。
音声 + 画面共有 · AIがリアルタイムで回答
画像生成
Flux、Nano Banana、Ideogram、Recraft + その他

思考の速度で書く。
AIオートコンプリート、リライト&コマンドで展開
あらゆるドキュメント。あらゆる形式。
PDF、URL、YouTube → チャット、クイズ、ポッドキャスト等
動画作成
Veo、Kling、MiniMax、Sora + その他

テキスト読み上げ
自然なAI音声、30以上の言語
コード生成
コードの作成、デバッグ、説明
ドキュメントとチャット
PDFをアップロード、コンテンツを分析
ポケットの中のAI。
iOS & Androidでフルアクセス · どこでも同期
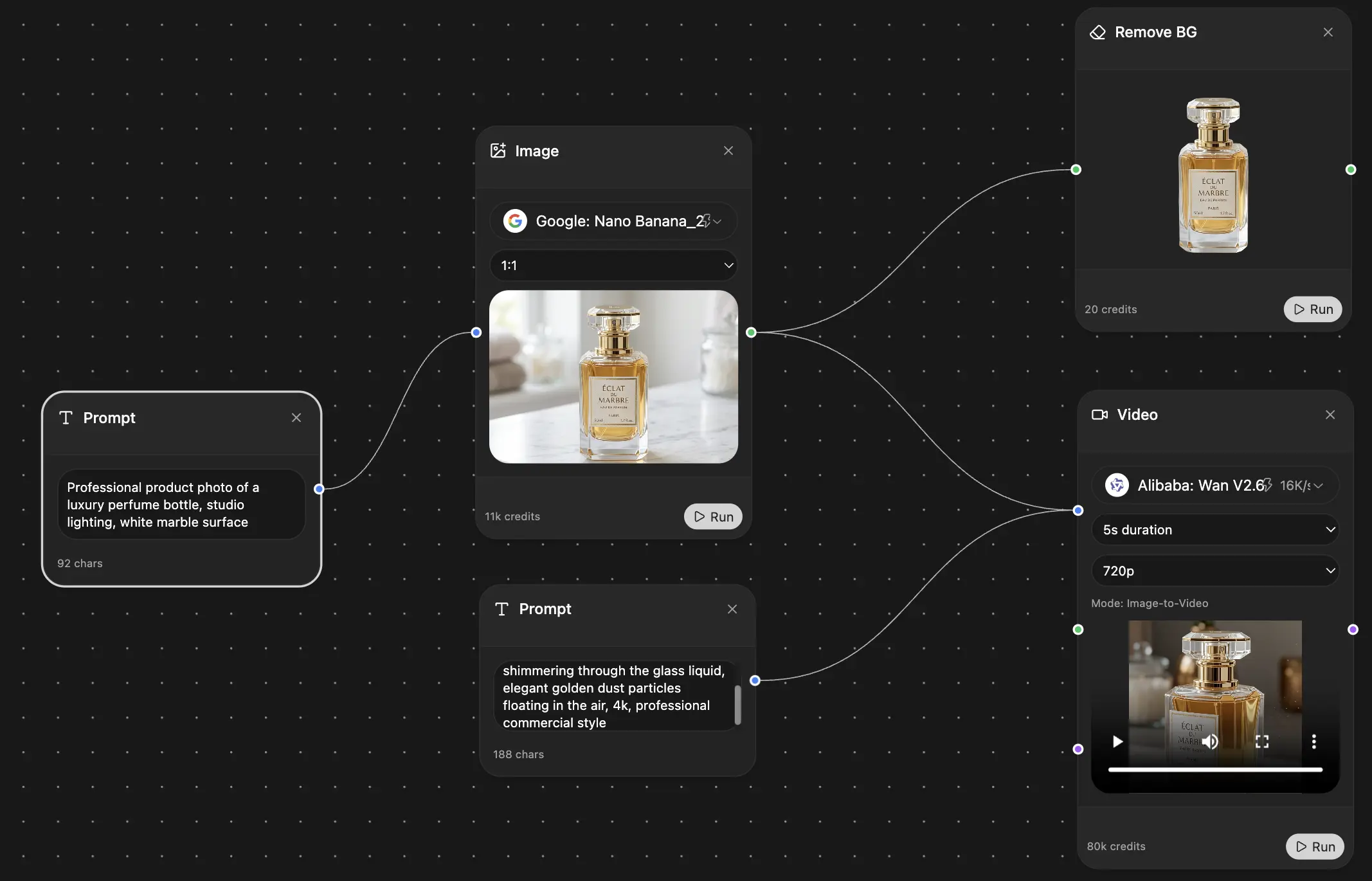
無限のAIキャンバス。
チャット、画像、動画&モーションツール — 並べて表示
作業と研究の時間を節約
シンプルで手頃な料金設定
信頼される企業チーム
無料
クレジットカード不要
- 毎日100クレジット
- 3つのAIモデルをお試し
- 基本AIチャット
Plus
- 1,000,000クレジット/月
- 25以上のAIモデル — GPT、Claude、Gemini、Grokなど
- Agent Mode:ウェブ検索、コンピュータツールなどを搭載
- Creative Studio:画像生成と動画生成
- Project Library:ドキュメント・ウェブサイト・YouTubeとチャット、ポッドキャスト生成、フラッシュカード、レポートなど
- Workflow StudioとFocusOS
Professional
- Plusのすべてと、
- 2,100,000クレジット/月
- Pro限定モデル(Claude Opus、Grok 4、Sonar Pro)
- Motion ToolsとMax Mode
- 最新機能への優先アクセス
- 追加特典へのアクセス