
AI 모델 테스트 방법: 필요한 유일한 가이드 (2025)
6단계 프레임워크를 사용하여 ChatGPT, Claude, Gemini와 같은 AI 모델을 테스트하는 방법을 배우세요. 실제 작업을 사용하여 AI 모델을 나란히 비교—기술적 기술이 필요하지 않습니다.
AI 모델 테스트 방법: 실제로 필요한 유일한 가이드
약 1년 전 Zemith를 구축할 때 AI 모델 테스트에 집착하기 시작했습니다. ML 연구원이라서가 아닙니다—그렇지 않습니다. 하지만 과대 광고에 계속 속았기 때문입니다.
모두 GPT-4가 최고라고 말했습니다. 그런 다음 Claude가 나왔고 사람들은 그것이 최고라고 말했습니다. 그런 다음 Gemini. 그런 다음 새로운 모델이 나오면 갑자기 그것이 왕이 되었습니다. 목표가 계속 움직였고, 저는 깨달았습니다: 어떤 AI 모델이 실제로 귀하의 필요에 맞는지 알고 싶다면 AI 모델을 직접 테스트해야 합니다.
벤치마크를 읽는 것이 아닙니다. 마케팅 주장을 신뢰하는 것이 아닙니다. 실제로 테스트하는 것입니다.
이것은 perplexity 점수나 BLEU 메트릭에 대한 기술 가이드가 아닙니다. 이것은 실제 사람들—창업자, 크리에이터, 개발자, 매일 AI를 사용하는 모든 사람—이 AI 모델을 평가하고 어떤 것이 실제로 작동하는지 알아내는 방법입니다.
일부 사람들은 비교를 위해 차트를 보는 것을 선호하지만, 실제 세계 결과는 종종 크게 다릅니다. 모델 응답이 무엇이고 어떻게 되는지 확실히 아는 유일한 방법은 실제 사용 테스트를 통하는 것입니다.
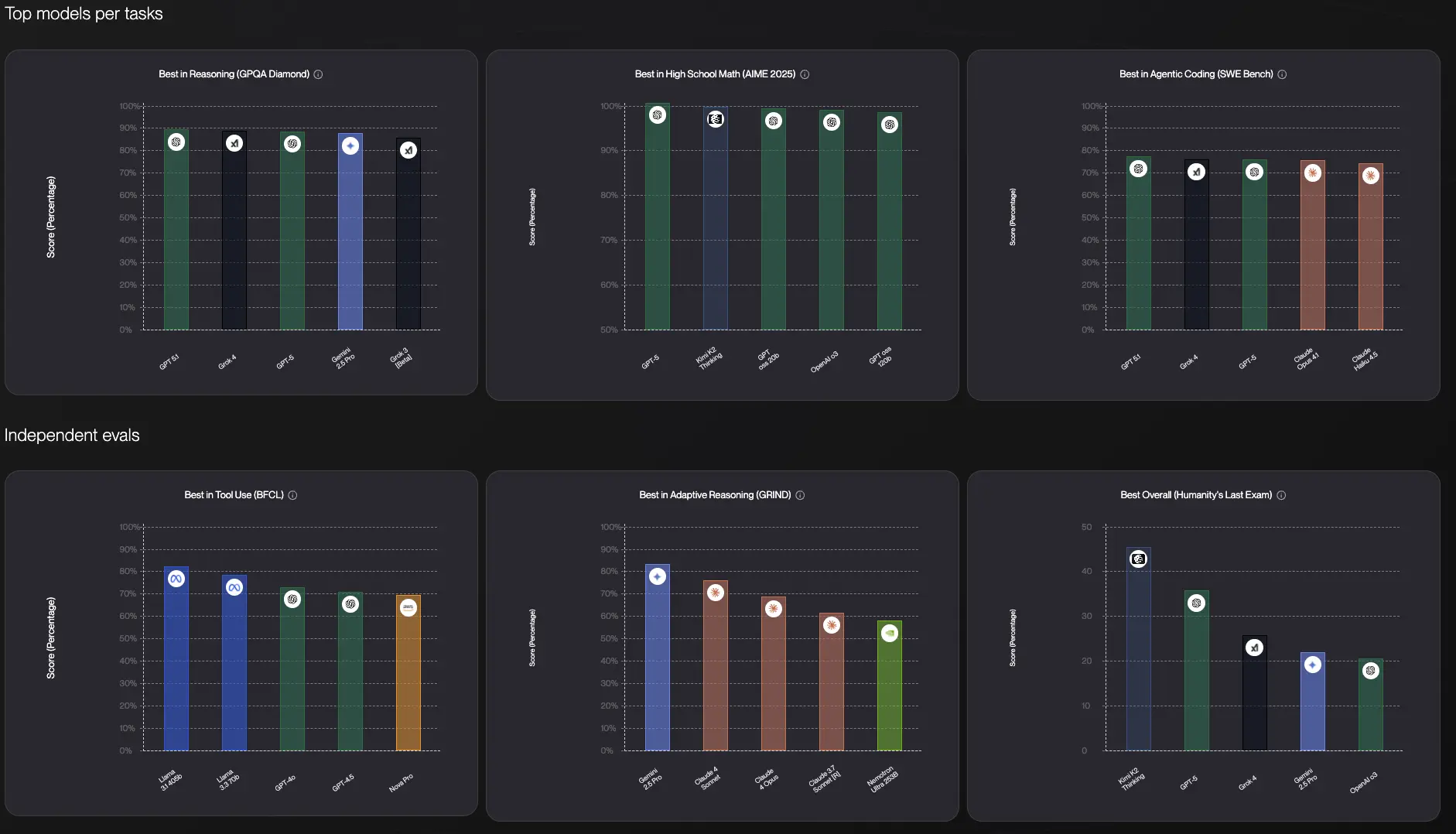
AI 모델을 직접 테스트하는 것이 필수적인 이유
이것이 제가 어려운 방법으로 배운 것입니다: AI 모델 벤치마크는 실제 작업에 기본적으로 쓸모가 없습니다.
모델이 일부 학술 테스트에서 우위를 점할 수 있지만, 그것이 귀하의 목소리로 이메일을 작성할지, 귀하의 업계 전문 용어를 이해할지, 또는 귀하의 비즈니스가 매일 다루는 이상한 엣지 케이스를 처리할지 알려주지 않습니다.
몇 달 동안 Reddit의 AI 모델에 대한 토론을 읽어왔는데, 반복되는 주제가 있습니다: 누군가 "어떤 AI를 사용해야 하나요?"라고 물으면 응답이 제각각입니다. 한 사람은 Claude가 코딩에서 무적이라고 맹세합니다. 다른 사람은 ChatGPT가 더 창의적이라고 말합니다. 다른 누군가는 Gemini가 가장 정확하다고 주장합니다. 그들은 모두 맞고 모두 틀렸습니다.
이러한 모델을 수천 번 테스트한 후, 진실은 이것입니다: 단일한 "최고의" AI 모델은 없습니다. 각각은 다른 강점을 가지고 있으며, 그 강점은 실제로 무엇을 하려고 하는지에 따라 다르게 중요합니다.
ChatGPT는 인간처럼 느껴지는 창의적이고 매력적인 콘텐츠를 제공할 수 있습니다. Claude는 분석에 완벽한 더 구조화되고 사려 깊은 응답을 제공할 수 있습니다. Gemini는 사실 연구에서 뛰어나며 긴 문서를 위한 거대한 컨텍스트 창을 가지고 있습니다.
어떤 모델이 귀하에게 가장 잘 작동하는지 아는 유일한 방법은 실제 사용 사례로 AI 모델을 테스트하는 것입니다. 가상의 것이 아닙니다. 일반적인 프롬프트가 아닙니다. 귀하의 실제 작업입니다.
모든 사람이 실제로 묻는 질문
AI 모델을 테스트하는 방법에 들어가기 전에, Reddit과 DM에서 지속적으로 보는 질문들을 다루겠습니다:
"모든 것에 ChatGPT만 사용할 수 있나요?"
할 수 있지만, 많은 것을 놓치게 됩니다. 때로는 적절한 드라이버가 정말 필요할 때 스위스 군용 칼을 사용하는 것과 같습니다.
"벤치마크로 충분하지 않나요?"
그렇지 않습니다. Claude가 일부 벤치마크에서 점수가 낮았지만 훨씬 더 나은 코드 설명을 제공했다고 지적한 Reddit 스레드를 봤습니다. 벤치마크는 연구원들이 중요하다고 생각하는 것을 측정하지만, 실제로 작업을 완료하는 데 도움이 되는 것은 아닙니다.
"한 응답이 다른 응답보다 더 나은지 어떻게 알 수 있나요?"
이것이 진짜 질문이며, 솔직히 말하면 생각보다 간단합니다. 답변을 사용하여 작업을 더 잘, 더 빠르게, 또는 더 적은 좌절로 완료할 수 있다면—그것이 귀하의 답변입니다.
"이것은 생각이 너무 많은 것 아닌가요?"
아마도, AI를 캐주얼하게 사용한다면. 하지만 비즈니스를 구축하고, 매일 콘텐츠를 작성하고, 또는 실제 작업에 AI에 의존한다면? 테스트는 생각이 너무 많은 것이 아닙니다—신중한 조사입니다.
AI 모델 테스트 방법: 6단계 프레임워크
기술 메트릭은 잊어버리세요. 언어 모델을 실제로 테스트하고 의미 있는 방식으로 AI 모델을 비교하는 방법은 다음과 같습니다:
1. 실제 작업으로 시작
"고양이에 대한 이야기를 쓰세요"와 같은 일반적인 프롬프트로 AI 모델을 테스트하지 마세요. 그것은 쓸모가 없습니다.
대신, 실제로 정기적으로 수행하는 3~5개의 작업을 선택하세요:
- 자주 보내는 특정 유형의 이메일 초안 작성
- 작업에서 일반적인 문서 요약
- 실제 프로젝트에 대한 아이디어 생성
- 실제로 구축 중인 것에 대한 코드 작성
- 받은 고객 지원 질문에 답변
이러한 작업이 더 구체적이고 실제적일수록, AI 모델 평가가 더 좋아집니다.
2. 다른 AI 모델에서 동일한 프롬프트 사용
AI 모델을 테스트할 때 이것이 중요합니다. 정확히 같은 프롬프트를 가져와서 ChatGPT, Claude, Gemini 및 고려 중인 다른 모델을 통해 실행하세요.
문구를 변경하지 마세요. 각 모델에 맞게 조정하지 마세요. 출력을 공정하게 비교할 수 있도록 동일한 입력을 사용하세요.
Zemith에서 이것을 처음 했을 때, 저는 충격을 받았습니다. 창의적인 브레인스토밍의 경우, ChatGPT는 일관되게 더 흥미로운 각도를 제공했습니다. 데이터 분석이나 복잡한 주제 분해의 경우, Claude가 더 명확하고 체계적이었습니다. 현재 정보로 사실 연구의 경우, Gemini가 앞서갔습니다.
누군가 같은 수수께끼로 세 모델을 모두 테스트한 훌륭한 Reddit 게시물을 봤습니다: "의사의 아들의 아버지가 의사가 아닐 수 있는 방법은 무엇입니까?" 세 모델 모두 정답을 얻었지만, 접근 방식은 완전히 달랐습니다. Claude는 가장 상세한 분석을 제공했고 문제를 생각하는 방식의 잠재적 편향까지 지적했습니다. ChatGPT는 간결하고 요점을 찔렀습니다. Gemini는 간단한 설명과 함께 정답을 제공했습니다.
모두 정확하고 모두 유용하지만, 각각 다른 스타일을 가지고 있습니다. 실제 작업에 어떤 것을 사용할지 결정할 때 이 차이가 중요합니다.
3. 메모리에서가 아닌 나란히 비교
인간의 기억은 비교에 끔찍합니다. 오늘 ChatGPT를 테스트하고 내일 Claude를 테스트하면, 각각이 무엇을 말했는지의 뉘앙스를 잊어버립니다.
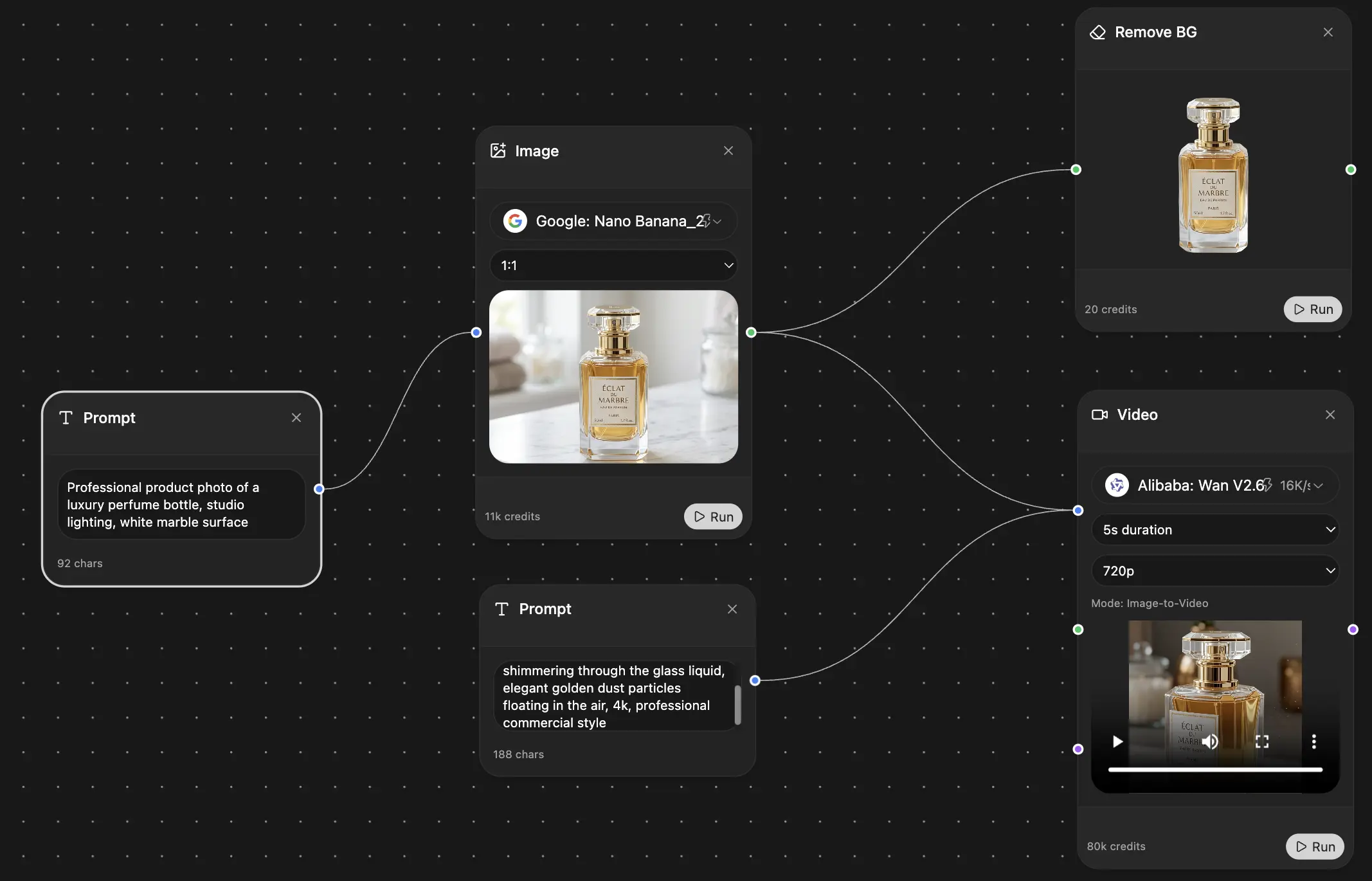
이것이 바로 Zemith에서 FocusOS를 구축한 이유입니다. 여러 탭에서 어떤 모델이 무엇을 말했는지 기억하려는 것은 악몽이기 때문입니다.
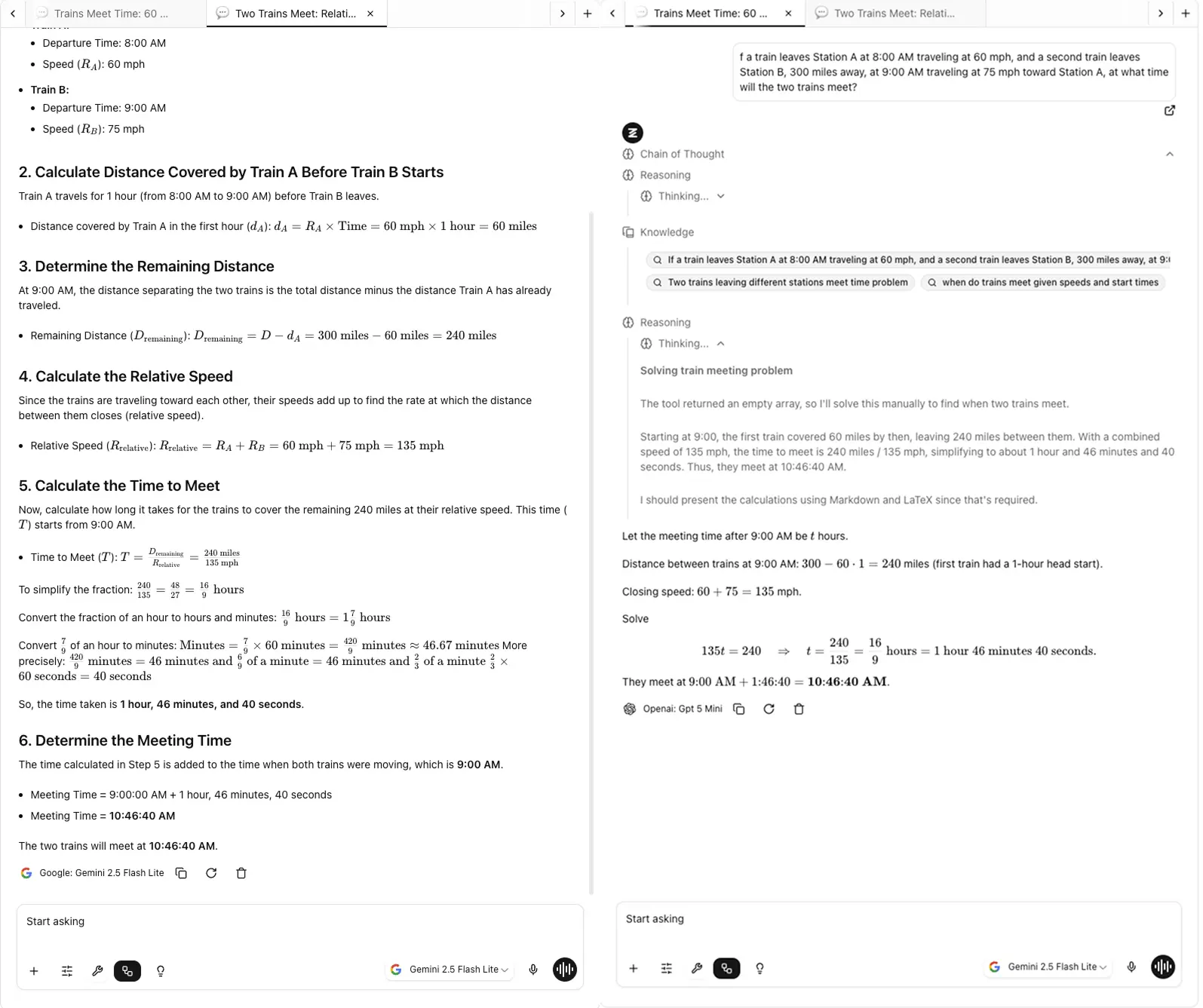
Zemith에서, 저는 Chrome과 같은 탭 시스템으로 Focus OS를 설계했습니다. 브라우저 탭을 저글링하지 않고 한 페이지에서 컨텍스트를 잃지 않고 빠르게 탭을 전환할 수 있습니다. 어떤 답변이 어떤 모델에서 왔는지 추적을 잃지 않습니다.
응답을 함께 보면 그렇지 않으면 놓칠 패턴이 드러납니다:
- 어떤 모델이 실제로 질문에 답하는지 vs. 어떤 것이 장황한지?
- 어떤 것이 선호하는 톤을 유지하는지?
- 어떤 것이 실제로 사용할 수 있는 정보를 제공하는지?
이것이 AI 모델을 테스트하는 최선의 방법입니다. 메모리에서 재구성하려고 하는 것이 아니라 실시간으로 차이를 보고 있기 때문입니다.
4. 일관성 및 AI 모델 성능 테스트
각 모델을 통해 같은 프롬프트를 몇 번 실행하세요. AI 모델은 확률적입니다—항상 같은 답변을 주지 않습니다.
일부 모델은 다른 모델보다 더 일관적입니다. 프로덕션 작업이나 고객 대면 콘텐츠에 AI를 사용하는 경우, 일관성이 중요합니다. 한 응답이 훌륭하고 다음 응답이 평범한 것을 원하지 않습니다.
AI 모델을 평가할 때, 일관성은 벤치마크가 잘 포착하지 못하는 핵심 메트릭입니다.
5. 환각 및 정확성 확인
사실적인 어떤 것에 AI를 사용하는 경우, 이것이 특히 중요합니다.
AI 모델은 때때로 자신 있게 무언가를 만들어냅니다. 존재하지 않는 연구를 인용하고, 제품이 가지고 있지 않은 기능을 참조하고, 완전히 잘못된 "사실"을 진술합니다.
정답을 알고 있는 질문을 하거나 모델에 출처를 인용하도록 요청하여 이를 테스트하세요. 그런 다음 해당 출처가 실제로 존재하고 모델이 주장하는 것을 말하는지 확인하세요.
언어 모델을 테스트한 경험에서, 그들은 여기서 크게 다릅니다. 일부는 다른 것보다 자신 있는 환각에 더 취약하며, 사실 작업에 신뢰할 수 있는 것을 알아야 합니다.
6. 결과 문서화
잘 작동한 것과 그렇지 않은 것에 대한 메모를 유지하세요. 미래의 자신이 감사할 것입니다. Zemith 노트 내에서도 노트를 저장할 수 있습니다. 노트 페이지로 이동하거나 FocusOS 내에서 새 노트 탭을 다시 열면 됩니다
저는 간단한 스프레드시트를 유지합니다:
- 작업 유형
- 테스트한 모델
- 승자 및 이유
- 주목할 만한 차이점
이런 식으로 AI 모델을 몇 주 동안 테스트한 후, 패턴이 나타납니다. 어떤 모델이 어떤 유형의 작업에서 일관되게 승리하는지 보기 시작할 것입니다.
AI 모델을 비교할 때 찾아야 할 것
세 가지 다른 모델의 응답을 응시하고 있을 때, AI 모델 평가에 실제로 중요한 것은 다음과 같습니다:
응답 품질: 실제로 질문한 것에 답하는가? 정보가 정확한가? 완전한가, 아니면 중요한 측면을 놓쳤는가?
톤과 스타일: 원하는 소리와 일치하는가? 일부 모델은 더 공식적이고, 다른 모델은 더 캐주얼합니다. Claude는 더 신중하고 사려 깊은 경향이 있다는 것을 알아챘습니다. ChatGPT는 더 역동적이고 대화적일 수 있습니다. 한 Reddit 사용자는 ChatGPT가 "더 매력적이고 좋아하는" 것이 되었지만 그것이 모든 것에 동의하는 "정교한 예스맨"이 된다고 경고했습니다. 진짜 비판이 필요하다면 명시적으로 요청해야 합니다.
깊이 vs. 간결함: 포괄적인 설명이 필요한가, 아니면 간결한 답변이 필요한가? 다른 모델은 다른 상세 수준으로 기본 설정됩니다. 세 가지 모두에서 같은 프롬프트를 테스트했습니다—ChatGPT는 한눈에 읽을 수 있는 가장 간결한 답변을 제공했고, Claude는 단계별 지침을 제공했으며, Gemini는 단계 없이 개요를 제공했습니다.
창의성 vs. 정확성: 창의적인 작업의 경우, 예상치 못한 아이디어를 원할 수 있습니다. 분석 작업의 경우, 정밀함을 원합니다. 하나에 최적화된 모델은 종종 다른 것에서 어려움을 겪습니다.
속도: AI를 대화형으로 사용하는 경우, 응답 시간이 중요합니다. AI 모델을 테스트할 때, 속도는 모델 간, 심지어 같은 모델의 다른 버전 간에 크게 다릅니다.
실제로 출처를 인용하는가?: 연구를 하는 경우, 이것이 중요합니다. Gemini는 실제 출처에 대한 링크를 제공하는 데 일관되게 더 좋습니다. ChatGPT는 때때로 오래된 정보를 제공합니다 (무료 버전은 2023년 말까지만 알고 있습니다). Claude는 역사적으로 출처에 연결하는 데 좋지 않았으며, 무언가를 확인해야 할 때 좌절스럽습니다.
AI 모델 비교: 수천 개의 프롬프트를 테스트하며 배운 것
다른 사용 사례에 대해 AI 모델을 비교할 때 알아챈 패턴은 다음과 같습니다:
글쓰기 및 콘텐츠 제작의 경우
ChatGPT는 창의적이고 매력적인 콘텐츠에서 뛰어납니다. 블로그 게시물, 마케팅 카피, 개성이 필요한 모든 것에 훌륭합니다. Twitter 훅을 테스트한 한 사용자는 "그들 중 아무도 훌륭하지 않다"고 말했지만 Claude가 최고의 결과를 제공했습니다—너무 장황하지 않고 불필요한 해시태그가 없습니다.
Claude는 사려 깊고 미묘한 글쓰기가 필요하거나 특정 스타일에 밀접하게 일치시키고 싶을 때 더 좋습니다. 특히 먼저 최고의 작품 예제를 제공할 때 글쓰기를 편집하는 데 사용합니다.
코딩의 경우
AI 모델을 직접 대결로 테스트할 때, 여기서 일이 흥미로워집니다.
본 테스트에서, "완전한 기능의 테트리스 게임을 만들라"고 요청했을 때, Claude는 점수와 컨트롤이 있는 아름답고 완전히 기능하는 게임을 구축했습니다. ChatGPT는 작동하는 기본적인 것을 만들었습니다. Gemini는 잘했지만 Claude의 수준에는 미치지 못했습니다.
그러나 Claude Sonnet의 비용은 Gemini Flash의 20배입니다. 비용이 중요한 AI 제품을 구축하는 경우, Gemini가 더 현명한 선택일 수 있습니다. Claude는 복잡한 작업에 대해 일관되게 더 깨끗한 코드와 더 나은 문서를 생성합니다.
연구 및 요약의 경우
Gemini는 거대한 컨텍스트 창으로 빛나며 사실적으로 더 정확한 경향이 있습니다. 거대한 문서를 소화하고 효율적으로 핵심 정보를 추출할 수 있습니다.
세 가지를 모두 테스트한 한 리뷰어는 Gemini를 "가장 일관된 올라운더"로 발견했으며 사실적이고 맥락적인 쿼리에서 특히 강합니다. Claude와 달리 실제 웹 검색도 내장되어 있습니다.
추론 및 문제 해결의 경우
추론 모델(OpenAI의 o1과 같은)은 복잡한 문제를 체계적으로 분해합니다. 계획, 전략 및 다단계 사고에 탁월합니다. 하지만 더 느립니다—때로는 응답하는 데 몇 분이 걸립니다.
분석 및 설명의 경우
이 목적으로 AI 모델을 평가할 때, Claude는 구조화된 논리적 분석을 제공합니다. 복잡한 아이디어를 분해하고 명확하게 설명하는 데 특히 좋습니다. 여러 Reddit 사용자가 Claude가 특히 논란의 여지가 있는 주제에서 "사려 깊고 균형 잡힌 논쟁"에 훌륭하다고 언급했습니다.
메모리 요인
언어 모델을 테스트할 때 놀라운 것—2025년에는 ChatGPT만 메모리가 있습니다. 대화를 넘어 귀하에 대한 세부 사항을 기억합니다. Gemini와 Claude는 그렇지 않습니다.
세션에서 세션으로 귀하의 선호도, 프로젝트, 글쓰기 스타일을 기억하는 AI가 필요한 경우, ChatGPT가 현재 유일한 선택입니다. 이것이 놀라운 이유는 ChatGPT가 과거 대화를 기반으로 제안하는 "마법 같은 순간"을 만들기 때문입니다.
ChatGPT vs Claude vs Gemini: 빠른 비교
| 기능 | ChatGPT | Claude | Gemini |
|---|---|---|---|
| 최적 | 창의적 콘텐츠, 일반 작업 | 코드, 분석, 편집 | 연구, 긴 문서 |
| 강점 | 매력적인 톤, 메모리 | 구조화된 사고, 깨끗한 코드 | 사실 정확성, 컨텍스트 |
| 약점 | "예스맨"이 될 수 있음 | 메모리 없음, 출처 적음 | 창의성 낮음 |
| 컨텍스트 창 | 128K 토큰 | 200K 토큰 | 1M 토큰 |
| 웹 검색 | 플러그인으로 | 내장 | 내장 |
| 비용 | 중간 | 최고 | 최저 (Flash) |
| 속도 | 빠름 | 빠름 | 다양함 |
하지만 가장 중요한 통찰은 이것입니다: 귀하의 결과는 다를 것입니다. 제 사용 사례에 작동하는 것이 귀하에게는 작동하지 않을 수 있습니다. 그것이 귀하 자신의 프롬프트로 AI 모델을 테스트해야 하는 이유입니다.
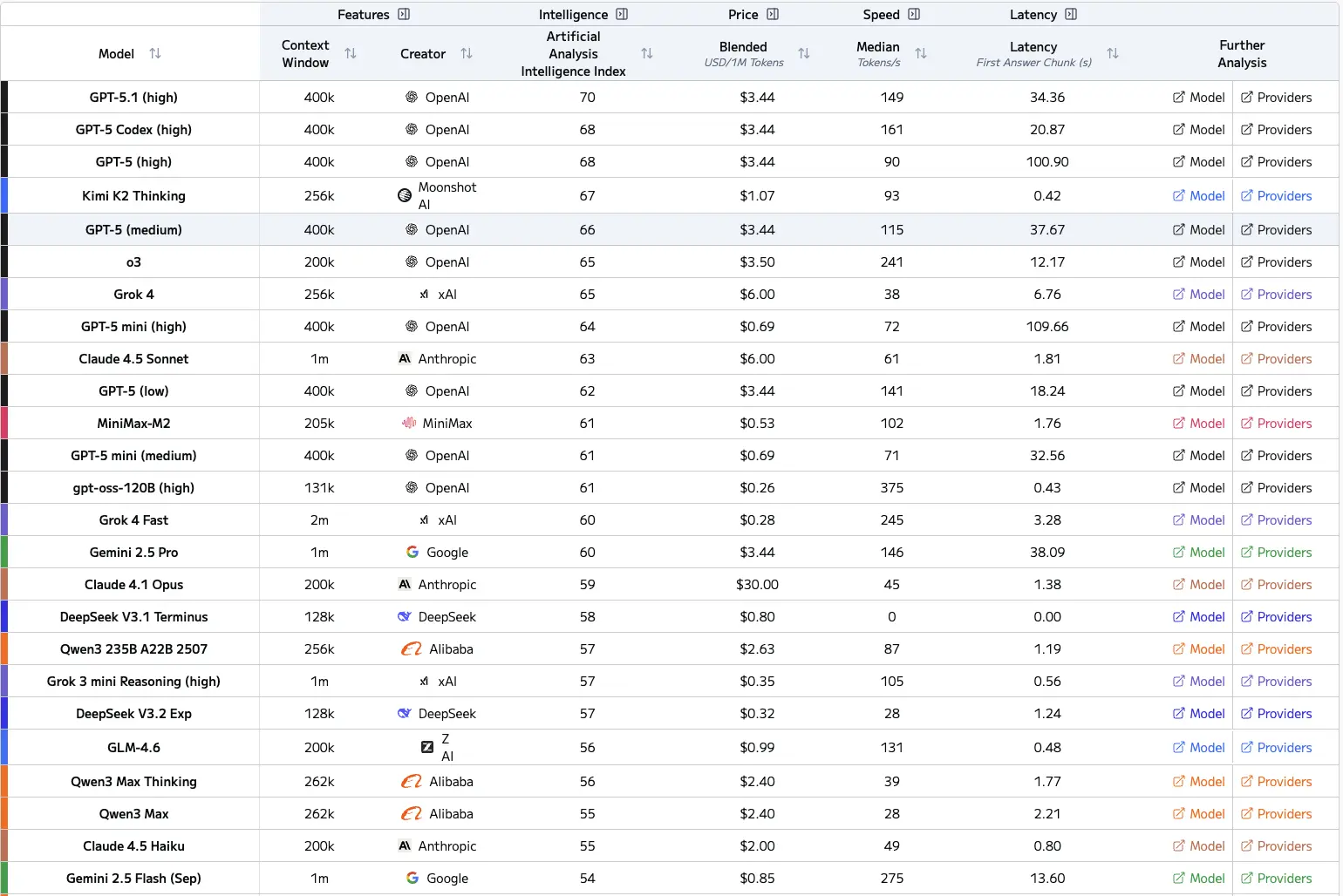
아래는 참고용 프론티어 LLM 차트이며 지능 지수도 포함되어 있습니다
AI 모델을 테스트하는 도구
다른 AI 모델을 테스트하는 가장 쉬운 방법은 나란히 사용하는 것입니다. 옵션은 다음과 같습니다:
옵션 1: 여러 탭 열기 - 무료이지만 성가십니다. 프롬프트를 ChatGPT, Claude 및 Gemini의 별도 탭에 복사-붙여넣기하세요. 수동으로 비교하세요.
옵션 2: Zemith의 Focus OS 사용 - 이것이 이 문제를 해결하기 위해 특별히 구축한 것입니다. FocusOS 탭 내에서 다른 모델을 사용하고, Chrome과 같은 탭 시스템으로 결과를 나란히 봅니다. 컨텍스트를 잃거나 창을 저글링하지 않고 모델 응답 간을 빠르게 전환할 수 있습니다. 시간을 절약하고 비교를 명확하게 만듭니다.
옵션 3: API 액세스 - 기술적인 경우, 스크립트를 작성하여 프로그래밍 방식으로 AI 모델을 테스트할 수 있습니다. 대량 테스트에 좋지만 코딩 지식이 필요합니다.
옵션 4: 기타 비교 도구 - Poe 또는 nat.dev와 같은 다른 플랫폼이 몇 가지 있지만 기능은 다양합니다.
핵심은 AI 모델을 무작위로 튕기는 것이 아니라 체계적인 비교 방법을 갖는 것입니다. Zemith의 Focus OS는 탭 기반 인터페이스로 이를 매우 간단하게 만듭니다—Chrome 탭을 생각하되, 각 탭은 프롬프트에 대한 다른 AI 모델의 응답입니다.
AI 모델을 테스트할 때 흔한 실수
이러한 실수를 모두 저지른 적이 있습니다. 제 고통에서 배우세요:
실수 1: 다른 프롬프트로 테스트 - 각 모델에 대해 문구를 약간 변경한 다음 결과가 다른 이유를 궁금해합니다. 동일한 프롬프트를 사용하세요.
실수 2: 한 번만 테스트 - 한 번의 테스트를 실행하고 승자를 선언합니다. AI 모델에는 가변성이 있습니다. 여러 번 테스트하세요.
실수 3: 비용 무시 - "최고의" 모델을 찾지만 비용이 20배 더 비쌉니다. 프로덕션 사용의 경우, 토큰당 비용이 중요합니다.
실수 4: 엣지 케이스 테스트 안 함 - 간단한 프롬프트로 모든 것이 훌륭하게 작동한 다음, 실제 사용 사례가 모든 것을 깨뜨립니다. 이상한 것을 테스트하세요.
실수 5: 주관적인 "느낌" 신뢰 - 한 모델의 개성이 좋아서 모든 것에 사용합니다. 캐주얼 사용에는 괜찮지만 비즈니스 결정에는 끔찍합니다.
실수 6: 결과 문서화 안 함 - 철저히 테스트하지만 아무것도 적지 않습니다. 3주 후, 어떤 모델이 무엇에 더 나았는지 기억하지 못합니다.
AI 모델을 테스트하는 데 얼마나 걸리나요?
솔직히? 약 일주일의 실제 사용으로 필요한 정보의 80%를 얻을 수 있습니다.
권장 사항은 다음과 같습니다:
- 1-2일: 모든 모델에서 상위 3-5개 작업을 테스트하세요. 승자를 문서화하세요.
- 3-5일: 실제 작업에서 각 작업 유형의 "승자"를 사용하세요. 문제를 기록하세요.
- 6-7일: 예상대로 작동하지 않은 것을 재테스트하세요. 선택을 조정하세요.
그 후, 언제 어떤 모델에 손을 뻗을지에 대한 확실한 감각을 갖게 될 것입니다. 시간이 지나면서 계속 학습하지만, 초기 투자는 단지 일주일의 주의를 기울이는 것입니다.
AI 모델을 테스트하는 최선의 방법은 공식 평가에 한 달을 보내는 것이 아닙니다. 짧은 기간 동안 정상적인 작업 중에 의도적으로 테스트하는 것입니다.
다중 모델 접근 방식
이것이 제가 실제로 지금 하는 것, 그리고 AI 모델을 테스트한 후 권장하는 것입니다:
하나의 "최고의" 모델을 선택하려고 하지 마세요. 다른 작업에 다른 모델을 사용하세요.
ChatGPT를 브레인스토밍과 창의적 콘텐츠의 첫 번째 초안에 사용합니다. 신중한 분석이나 편집이 필요할 때 Claude를 사용합니다. 큰 문서를 작업하거나 웹에서 현재 정보가 필요할 때 Gemini를 사용합니다.
이것이 Zemith를 여러 모델을 지원하도록 구축한 이유입니다. 미래는 하나의 완벽한 AI를 찾는 것이 아닙니다—각 작업에 적합한 도구를 갖는 것입니다.
스마트폰에 다른 앱이 있는 것처럼 생각하세요. 이메일에 Instagram을 사용하거나 사진에 Gmail을 사용하지 않습니다. 목적에 따라 다른 도구입니다.
AI 모델을 제대로 비교하고 평가하면, 전문화가 일반화를 이긴다는 것을 깨닫게 됩니다.
AI 모델을 효과적으로 테스트하는 실용적인 팁
작게 시작: 한 번에 모든 것을 테스트하려고 하지 마세요. 세 가지 일반적인 작업을 선택하고 먼저 철저히 테스트하세요.
구체적으로: 모호한 프롬프트는 모호한 결과를 제공합니다. 실제 작업에서 사용할 실제, 구체적인 프롬프트로 테스트하세요.
엣지 케이스 테스트: 행복한 경로만 테스트하지 마세요. 모호하고 복잡하거나 비정상적인 프롬프트를 시도하세요. 거기서 AI 모델 성능의 실제 차이를 볼 수 있습니다.
비용 고려: 일부 모델은 다른 모델보다 더 비쌉니다. 대량 작업을 하는 경우, AI 모델을 평가할 때 가격을 고려하세요. 10배 더 저렴한 약간 더 나쁜 모델이 더 나은 선택일 수 있습니다.
프롬프트 반복: 때로는 모델 약점처럼 보이는 것이 실제로는 프롬프트 문제입니다. 어떤 모델에서도 결과가 좋지 않으면 프롬프트를 수정하세요.
최신 상태 유지: 모델은 지속적으로 개선됩니다. 오늘 사실인 것이 다음 달에는 바뀔 수 있습니다. 중요한 사용 사례로 주기적으로 재테스트하세요. AI 모델을 테스트하는 최선의 방법에는 정기적인 재평가가 포함됩니다.
발견 공유: 언어 모델 테스트에 대해 논의하는 커뮤니티에 참여하세요. 다른 사람의 경험에서 배우고 고려하지 않은 사용 사례를 발견할 것입니다.
FAQ: AI 모델 테스트
AI 모델을 테스트하려면 기술적 기술이 필요합니까?
아니요. 텍스트를 복사-붙여넣기할 수 있다면 AI 모델을 테스트할 수 있습니다. 제가 설명한 접근 방식은 코딩이나 기술적 지식이 필요하지 않습니다.
AI 모델을 테스트하는 최선의 무료 방법은 무엇입니까?
ChatGPT, Claude 및 Gemini의 무료 계정을 엽니다. 여러 탭을 사용하세요. 투박하지만 작동합니다. 대부분의 모델에는 테스트에 충분한 무료 티어가 있습니다.
얼마나 자주 AI 모델을 테스트해야 합니까?
작업에 AI를 처음 사용하기 시작할 때 철저한 평가를 수행하세요. 그런 다음 모델이 개선됨에 따라 3-4개월마다 재테스트하세요. 새로운 주요 모델이 출시될 때도 테스트하세요.
AI 모델 벤치마크를 전혀 신뢰할 수 있습니까?
무용하지 않지만 제한적입니다. 벤치마크는 이론적 능력을 알려줍니다. 귀하의 테스트는 귀하의 특정 필요에 대한 실제 성능을 알려줍니다. 둘 다 사용하세요.
모든 단일 작업에 대해 AI 모델을 테스트해야 합니까?
아니요. 가장 일반적인 작업과 가장 중요한 작업을 테스트하세요. 변형에 어떤 모델을 사용할지에 대한 직관을 빠르게 개발할 것입니다.
"최고의" 모델이 너무 비싸면 어떻게 해야 합니까?
그렇다면 실제로 귀하에게 최고의 모델이 아닙니다. 최고의 모델은 귀하의 사용 사례에 의미 있는 가격으로 충분히 좋은 결과를 제공하는 모델입니다.
AI 모델 테스트 방법에 대한 결론
AI 모델 테스트는 복잡할 필요가 없습니다. 기술적 전문 지식이나 멋진 평가 프레임워크가 필요하지 않습니다.
실제 작업으로 모델을 사용하고, 결과를 나란히 비교하고, 무엇이 작동하는지 주의를 기울이기만 하면 됩니다.
Reddit에서 누군가 테스트 프로세스를 완벽하게 설명하는 것을 봤습니다: "카페인으로 작동하는 핀볼처럼 AI 도구 사이를 튕기고 있습니다. 한 순간 Claude에게 단락을 다시 쓰라고 요청하고, 다음 순간 ChatGPT로 디버깅하고, 그런 다음 PDF를 Gemini에 넘깁니다." 이것이 우리 대부분이 이러한 도구를 사용하는 방식입니다—실용적으로, 그때 필요한 것에 따라 전환합니다.
귀하의 특정 필요에 최상의 결과를 제공하는 AI—그것이 귀하의 답변입니다. 가장 높은 벤치마크 점수를 가진 것이 아닙니다. 모든 사람이 이야기하는 것이 아닙니다. 실제로 귀하를 위해 작동하는 것입니다.
AI 모델을 제대로 테스트하고 비교하면, 과대 광고에 의존하는 것을 멈추고 자신의 경험에서 나온 데이터에 의존하기 시작합니다.
이것이 Zemith를 구축한 이유입니다. AI 모델 선택은 마케팅 주장이나 이론적 벤치마크가 아닌 실제 작업으로 실제 테스트에 기반해야 하기 때문입니다.
여러 모델을 시도하세요. 직접 비교하세요. 작동하는 것을 찾으세요. 그렇게 간단합니다.
그리고 솔직히? 여러 모델을 사용하는 것—각각이 가장 잘하는 것—이 하나의 모델에 모든 것을 강제하는 것보다 더 나을 수 있습니다.
어쨌든 이것이 제 경험입니다. 그리고 일단 직접 테스트를 시작하면 귀하의 경험도 될 것이라고 확신합니다.
쉬운 방법으로 AI 모델을 테스트하고 싶으신가요? Focus OS 인터페이스로 ChatGPT, Claude, Gemini 등을 나란히 사용할 수 있는 Zemith를 확인하세요. 하나의 구독 플랜으로 몇 초 만에 모델 응답 간을 전환할 수 있는 올인원 AI 앱
Zemith 기능 탐색
모든 최고 AI. 하나의 구독.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ 모델












항상 켜진 실시간 AI.
음성 + 화면 공유 · 즉각적인 답변
새로운 언어를 배우는 가장 좋은 방법은 무엇인가요?
몰입과 간격 반복이 가장 효과적입니다. 매일 목표 언어의 미디어를 소비해 보세요.
음성 + 화면 공유 · AI가 실시간으로 답변
이미지 생성
Flux, Nano Banana, Ideogram, Recraft + 더보기

생각의 속도로 쓰세요.
AI 자동완성, 다시쓰기 & 명령으로 확장
모든 문서. 모든 형식.
PDF, URL 또는 YouTube → 채팅, 퀴즈, 팟캐스트 등
영상 제작
Veo, Kling, MiniMax, Sora + 더보기

텍스트 음성 변환
자연스러운 AI 음성, 30개 이상 언어
코드 생성
코드 작성, 디버그 및 설명
문서와 채팅
PDF 업로드, 콘텐츠 분석
주머니 속의 AI.
iOS & Android 전체 이용 · 어디서나 동기화
무한한 AI 캔버스.
채팅, 이미지, 영상 & 모션 도구 — 나란히
업무 및 연구 시간을 절약하세요
간단하고 합리적인 가격
신뢰하는 기업 팀
무료
신용카드 불필요
- 매일 100 크레딧
- 3개의 AI 모델 체험
- 기본 AI 채팅
플러스
- 1,000,000 크레딧/월
- 25개 이상의 AI 모델 — GPT, Claude, Gemini, Grok 등
- Agent Mode: 웹 검색, 컴퓨터 도구 등 포함
- Creative Studio: 이미지 생성 및 비디오 생성
- Project Library: 문서, 웹사이트, YouTube와 채팅, 팟캐스트 생성, 플래시카드, 리포트 등
- Workflow Studio 및 FocusOS
프로페셔널
- 플러스의 모든 것, 그리고:
- 2,100,000 크레딧/월
- Pro 전용 모델 (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- 최신 기능 우선 이용
- 추가 혜택 이용 가능