
Як тестувати моделі ШІ: Єдиний посібник, який вам потрібен (2025)
Дізнайтеся, як тестувати моделі ШІ, такі як ChatGPT, Claude та Gemini, за допомогою нашої 6-крокової структури. Порівняйте моделі ШІ поруч, використовуючи реальні завдання—технічні навички не потрібні.
Як тестувати моделі ШІ: Єдиний посібник, який вам дійсно потрібен
Я почав нав'язливо тестувати моделі ШІ приблизно рік тому, коли будував Zemith. Не тому, що я якийсь дослідник ML—я не є. А тому, що я постійно обпікався на хайпі.
Усі говорили, що GPT-4 найкращий. Потім з'явився Claude, і люди сказали, що він найкращий. Потім Gemini. Потім якась нова модель з'являлася, і раптом вона ставала королем. Мета постійно рухалася, і я зрозумів: якщо ви хочете знати, яка модель ШІ дійсно працює для ваших потреб, вам доведеться тестувати моделі ШІ самостійно.
Не читати бенчмарки. Не довіряти маркетинговим заявам. Дійсно тестувати їх.
Це не технічний посібник про оцінки заплутаності або метрики BLEU. Це те, як реальні люди—засновники, творці, розробники, будь-хто, хто щодня використовує ШІ—повинні оцінювати моделі ШІ та з'ясовувати, яка з них працює.
Хоча деякі люди віддають перевагу перегляду графіків для порівняння, часто реальний результат у світі сильно відрізняється. Єдиний спосіб точно знати, що таке відповідь моделі та як вона працює,—це через реальне тестування використання.
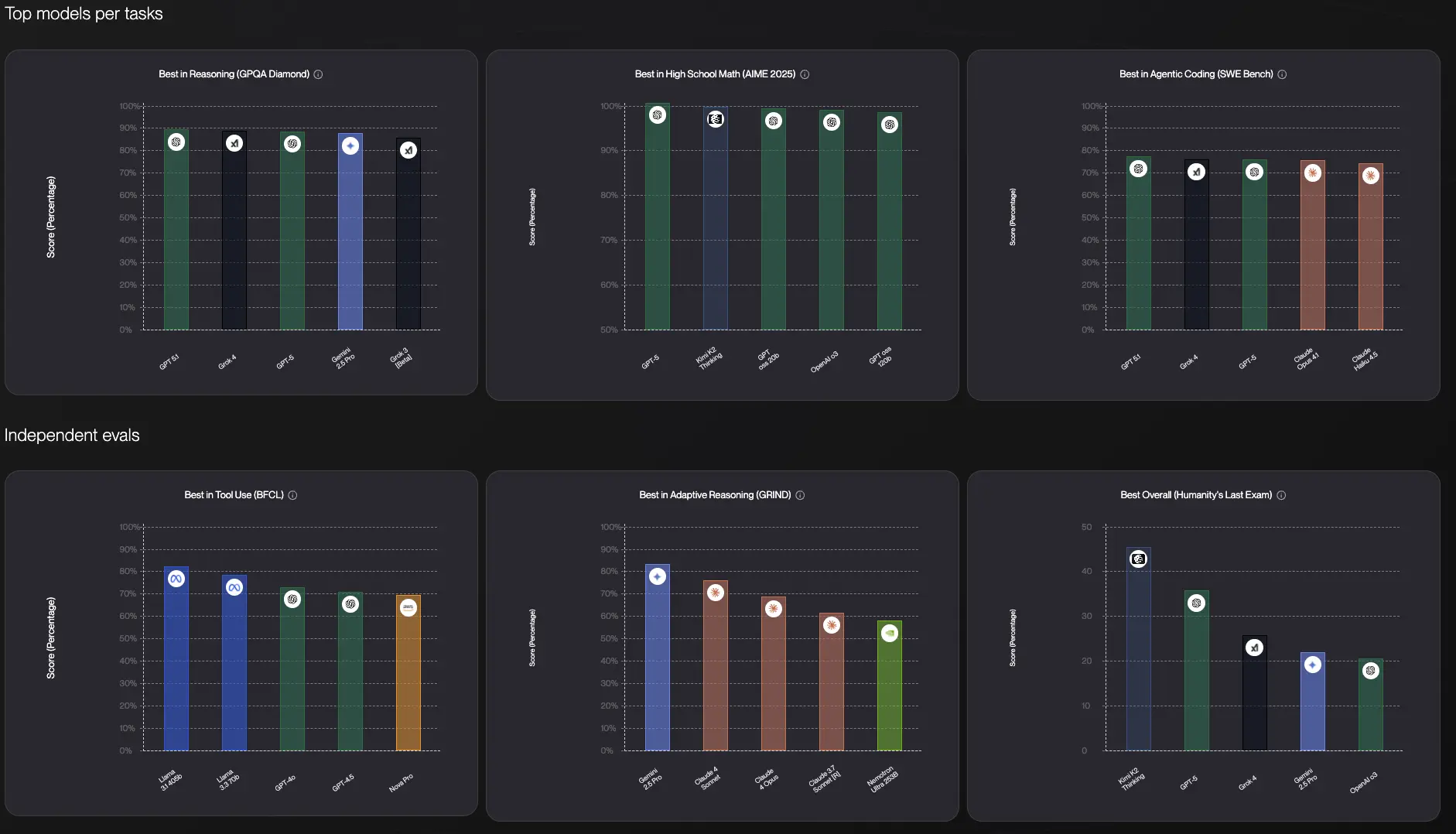
Чому тестування моделей ШІ самостійно є обов'язковим
Ось що я дізнався важким шляхом: бенчмарки моделей ШІ в основному марні для вашої реальної роботи.
Модель може домінувати в якомусь академічному тесті, але це не каже вам, чи вона писатиме електронні листи вашим голосом, розумітиме жаргон вашої галузі або оброблятиме дивні крайові випадки, з якими ваша компанія має справу щодня.
Я читаю обговорення Reddit про моделі ШІ вже кілька місяців, і є повторювана тема: хтось запитує "яку ШІ мені використовувати?" і відповіді скрізь. Одна людина клянеться, що Claude непереможний для програмування. Інша каже, що ChatGPT більш креативний. Хтось інший наполягає, що Gemini найточніший. Всі вони праві, і всі вони помиляються.
Після тестування цих моделей тисячі разів, ось правда: немає єдиної "найкращої" моделі ШІ. Кожна має різні сильні сторони, і ці сильні сторони мають різне значення залежно від того, що ви насправді намагаєтеся зробити.
ChatGPT може дати вам креативний, захоплюючий контент, який здається людським. Claude може надати більш структуровані, продумані відповіді, ідеальні для аналізу. Gemini вирізняється фактичним дослідженням і має величезне вікно контексту для довгих документів.
Єдиний спосіб дізнатися, яка модель працює найкраще для вас,—це тестувати моделі ШІ з вашими реальними випадками використання. Не гіпотетичними. Не загальними запитами. Ваша реальна робота.
Питання, які всі насправді ставлять
Перш ніж ми перейдемо до того, як тестувати моделі ШІ, дозвольте мені звернутися до питань, які я постійно бачу на Reddit і в DM:
"Чи можу я просто використовувати ChatGPT для всього?"
Ви могли б, але ви багато втрачаєте. Це як використовувати швейцарський ніж, коли іноді вам дійсно потрібна належна викрутка.
"Чи недостатньо бенчмарків?"
Не зовсім. Я бачив нитку Reddit, де хтось зазначив, що Claude отримав нижчий бал у якомусь бенчмарку, але дав їм набагато кращі пояснення коду. Бенчмарки вимірюють те, що дослідники вважають важливим, а не те, що насправді допомагає вам виконувати роботу.
"Як я взагалі можу знати, чи одна відповідь краща за іншу?"
Це справжнє питання, і, чесно кажучи, це простіше, ніж ви думаєте. Якщо ви можете використати відповідь, щоб виконати своє завдання краще, швидше або з меншим розчаруванням—це ваша відповідь.
"Чи це не просто надмірне мислення?"
Можливо, якщо ви використовуєте ШІ випадково. Але якщо ви будуєте бізнес, пишете контент щодня або покладаєтеся на ШІ для реальної роботи? Тестування—це не надмірне мислення—це належна обережність.
Як тестувати моделі ШІ: 6-крокова структура
Забудьте про технічні метрики. Ось як насправді тестувати мовні моделі та порівнювати моделі ШІ способом, який має значення:
1. Почніть зі своїх реальних завдань
Не тестуйте моделі ШІ загальними запитами на кшталт "напишіть історію про кота". Це марно.
Замість цього візьміть три-п'ять завдань, які ви насправді регулярно виконуєте:
- Напишіть чернетку конкретного типу електронного листа, який ви часто надсилаєте
- Підсумуйте типовий документ з вашої роботи
- Створіть ідеї для ваших реальних проектів
- Напишіть код для чогось, що ви насправді будуєте
- Дайте відповідь на питання служби підтримки клієнтів, яке ви отримали
Чим більш конкретними та реальними є ці завдання, тим кращею буде ваша оцінка моделі ШІ.
2. Використовуйте ідентичні запити в різних моделях ШІ
Це критично, коли ви тестуєте моделі ШІ. Візьміть точно той самий запит і запустіть його через ChatGPT, Claude, Gemini та будь-які інші моделі, які ви розглядаєте.
Не змінюйте формулювання. Не налаштовуйте його для кожної моделі. Використовуйте ідентичні вхідні дані, щоб ви могли справедливо порівняти вихідні дані.
Коли я вперше зробив це в Zemith, я був шокований. Для креативного мозкового штурму ChatGPT постійно давав мені більш цікаві кути. Для аналізу даних або розбиття складних тем Claude був чіткішим і організованішим. Для фактичного дослідження з поточною інформацією Gemini вирвався вперед.
Я бачив чудовий пост Reddit, де хтось тестував усі три моделі з тією ж загадкою: "Як можливо, що батько сина лікаря не є лікарем?" Усі троє отримали правильну відповідь, але їхні підходи були повністю різними. Claude дав найдетальніший розбір і навіть вказав на потенційні упередження в тому, як ми думаємо про проблему. ChatGPT був лаконічним і по суті. Gemini дав правильну відповідь з коротким поясненням.
Усі правильні, усі корисні, але кожен з іншим стилем. Ця різниця має значення, коли ви вирішуєте, яку використовувати для своєї реальної роботи.
3. Порівнюйте поруч, а не з пам'яті
Людська пам'ять жахлива для порівнянь. Якщо ви тестуєте ChatGPT сьогодні, а Claude завтра, ви забудете нюанси того, що сказав кожен.
Саме тому я побудував FocusOS на Zemith, тому що спроба згадати, яка модель що сказала в кількох вкладках,—це кошмар.
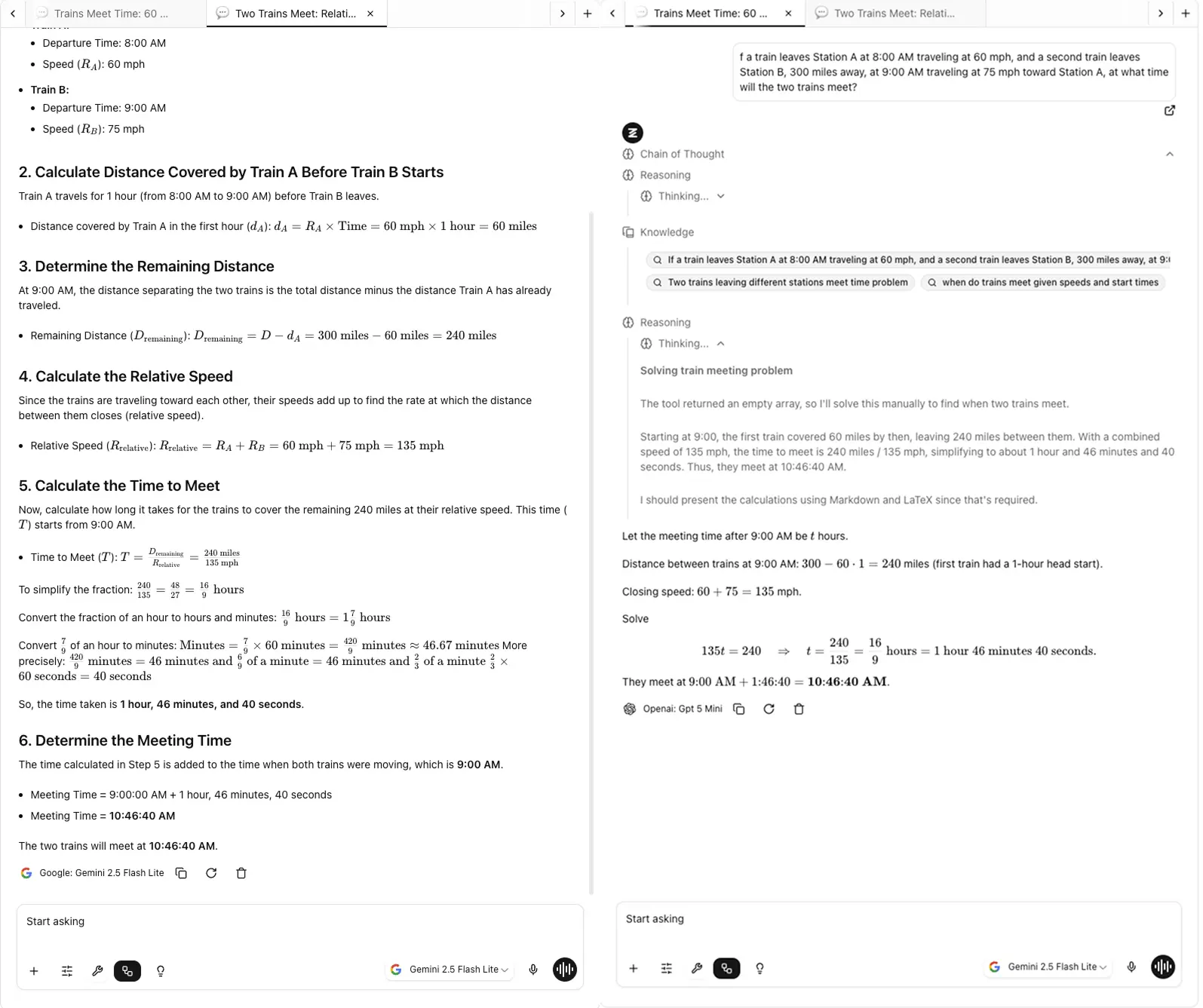
У Zemith я розробив Focus OS з системою вкладок, подібною до Chrome, щоб ви могли швидко перемикатися між вкладками, не втрачаючи контексту з однієї сторінки, не жонглюючи вкладками браузера, не втрачаючи відстеження того, яка відповідь походить від якої моделі.
Перегляд відповідей разом виявляє закономірності, які ви інакше пропустили б:
- Яка модель насправді відповідає на ваше питання проти тієї, що базікає?
- Яка підтримує ваш бажаний тон?
- Яка дає вам інформацію, яку ви насправді можете використати?
Це найкращий спосіб тестувати моделі ШІ, тому що ви бачите відмінності в реальному часі, а не намагаєтеся відновити їх з пам'яті.
4. Тестуйте на послідовність та продуктивність моделі ШІ
Запустіть той самий запит через кожну модель кілька разів. Моделі ШІ є ймовірнісними—вони не завжди дають однакову відповідь.
Деякі моделі більш послідовні, ніж інші. Якщо ви використовуєте ШІ для роботи в продакшні або контенту, орієнтованого на клієнтів, послідовність має значення. Ви не хочете, щоб одна відповідь була блискучою, а наступна—середньою.
Коли ви оцінюєте моделі ШІ, послідовність—це ключова метрика, яку бенчмарки не добре захоплюють.
5. Перевірте на галюцинації та точність
Це особливо важливо, якщо ви використовуєте ШІ для чогось фактичного.
Моделі ШІ іноді впевнено вигадують речі. Вони цитуватимуть дослідження, яких не існує, посилатимуться на функції, яких продукти не мають, або заявлятимуть "факти", які повністю неправильні.
Тестуйте це, ставлячи питання, де ви знаєте правильну відповідь, або просячи модель цитувати джерела. Потім перевірте, чи ці джерела дійсно існують і кажуть те, що стверджує модель.
У моєму досвіді тестування мовних моделей вони значно відрізняються тут. Деякі більш схильні до впевнених галюцинацій, ніж інші, і вам потрібно знати, яким можна довіряти для фактичної роботи.
6. Документуйте свої результати
Ведіть записи про те, що працювало добре, а що ні. Ваше майбутнє "я" подякує вам. Ви також можете зберегти нотатки в Zemith note, перейшовши на сторінку нотаток або просто відкривши нову вкладку нотаток у FocusOS знову
Я веду просту таблицю:
- Тип завдання
- Які моделі я тестував
- Переможець і чому
- Будь-які помітні відмінності
Після кількох тижнів тестування моделей ШІ таким чином з'являються закономірності. Ви почнете бачити, яка модель постійно виграє для якого типу завдання.
На що звертати увагу при порівнянні моделей ШІ
Коли ви дивитеся на відповіді від трьох різних моделей, ось що насправді має значення для вашої оцінки моделі ШІ:
Якість відповіді: Чи вона насправді відповідає на те, що ви запитали? Чи точна інформація? Чи вона повна, чи пропустила важливі аспекти?
Тон і стиль: Чи відповідає він тому, як ви хочете звучати? Деякі моделі більш формальні, інші більш неформальні. Я помітив, що Claude має тенденцію бути більш виміряним і продуманим. ChatGPT може бути більш динамічним і розмовним. Один користувач Reddit сказав, що ChatGPT став "більш захоплюючим і приємним", але попередив, що це робить його "вишуканим підлабузником", який згоден з усім. Якщо вам потрібна справжня критика, ви повинні явно її попросити.
Глибина проти стислості: Чи потрібні вам всебічні пояснення чи стислі відповіді? Різні моделі за замовчуванням мають різні рівні деталізації. Я тестував той самий запит на всіх трьох—ChatGPT дав мені найстислішу відповідь, яку можна прочитати одним поглядом, Claude надав покрокові інструкції, а Gemini дав огляд без кроків.
Креативність проти точності: Для креативних завдань вам можуть знадобитися несподівані ідеї. Для аналітичної роботи вам потрібна точність. Моделі, оптимізовані для одного, часто борються з іншим.
Швидкість: Якщо ви використовуєте ШІ інтерактивно, час відповіді має значення. Коли я тестую моделі ШІ, швидкість значно варіюється між моделями і навіть між різними версіями тієї самої моделі.
Чи вона насправді цитує джерела?: Це величезне, якщо ви займаєтеся дослідженням. Gemini постійно краще надає посилання на реальні джерела. ChatGPT іноді дасть вам застарілу інформацію (він знає лише до кінця 2023 року у безкоштовній версії). Claude історично не був чудовим у посиланні на джерела, що розчаровує, коли вам потрібно щось перевірити.
Порівняння моделей ШІ: Що я дізнався, тестуючи тисячі запитів
Ось закономірності, які я помітив при порівнянні моделей ШІ для різних випадків використання:
Для письма та створення контенту
ChatGPT вирізняється креативним, захоплюючим контентом. Він чудовий для постів у блогах, маркетингових текстів і всього, що потребує особистості. Один користувач, який тестував Twitter-хуки, сказав "жоден з них не чудовий", але Claude дав найкращий результат—не надто багатослівний, без непотрібних хештегів.
Claude кращий, коли вам потрібне продумане, нюансоване письмо або ви хочете точно відповідати певному стилю. Я використовую його для редагування свого письма, особливо коли спочатку даю йому приклади своєї найкращої роботи.
Для програмування
Тут стає цікаво, коли ви тестуєте моделі ШІ один на один.
У тестах, які я бачив, коли просили "створити повнофункціональну гру Tetris", Claude створив чудову, повністю функціональну гру з очками та керуванням. ChatGPT створив щось базове, що працює. Gemini зробив добре, але не зовсім на рівні Claude.
Однак Claude Sonnet коштує у 20 разів більше, ніж Gemini Flash. Якщо ви будуєте продукт ШІ, де важлива вартість, Gemini може бути розумнішим вибором. Claude постійно виробляє чистіший код з кращою документацією для складних завдань.
Для дослідження та підсумкування
Gemini вирізняється своїм величезним вікном контексту і має тенденцію бути більш фактично точним. Він може переварити величезні документи та ефективно витягти ключову інформацію.
Один рецензент, який тестував усі три, знайшов Gemini "найбільш послідовним універсалом" і особливо сильним у фактичних, контекстних запитах. Він також має вбудований реальний веб-пошук, на відміну від Claude.
Для міркувань та вирішення проблем
Моделі міркувань (як o1 від OpenAI) систематично розбивають складні проблеми. Вони чудові для планування, стратегії та багатоетапного мислення. Але вони повільніші—іноді потрібно кілька хвилин, щоб відповісти.
Для аналізу та пояснень
Claude надає структурований, логічний аналіз, коли ви оцінюєте моделі ШІ для цієї мети. Він особливо хороший у розбитті складних ідей та їх чіткому поясненні. Кілька користувачів Reddit згадали, що Claude чудовий для "продуманих, збалансованих аргументів", особливо на суперечливі теми.
Фактор пам'яті
Ось щось, що мене здивувало під час тестування мовних моделей—у 2025 році лише ChatGPT має пам'ять. Він пам'ятає деталі про вас у різних розмовах. Gemini і Claude не мають.
Якщо вам потрібна ШІ, яка пам'ятає ваші уподобання, ваші проекти, ваш стиль письма від сесії до сесії, ChatGPT наразі є вашим єдиним варіантом. Я вважаю це диким, тому що це створює ці "магічні моменти", коли ChatGPT пропонує речі на основі минулих розмов.
ChatGPT vs Claude vs Gemini: Швидке порівняння
| Функція | ChatGPT | Claude | Gemini |
|---|---|---|---|
| Найкраще для | Креативний контент, загальні завдання | Код, аналіз, редагування | Дослідження, довгі документи |
| Сильні сторони | Захоплюючий тон, пам'ять | Структуроване мислення, чистий код | Фактична точність, контекст |
| Слабкі сторони | Може бути "підлабузником" | Немає пам'яті, менше джерел | Менш креативний |
| Вікно контексту | 128K токенів | 200K токенів | 1M токенів |
| Веб-пошук | З плагінами | Вбудований | Вбудований |
| Вартість | Середня | Найвища | Найнижча (Flash) |
| Швидкість | Швидка | Швидка | Варіюється |
Але ось найважливіше розуміння: ваш результат буде відрізнятися. Те, що працює для моїх випадків використання, може не працювати для ваших. Ось чому вам потрібно тестувати моделі ШІ зі своїми власними запитами.
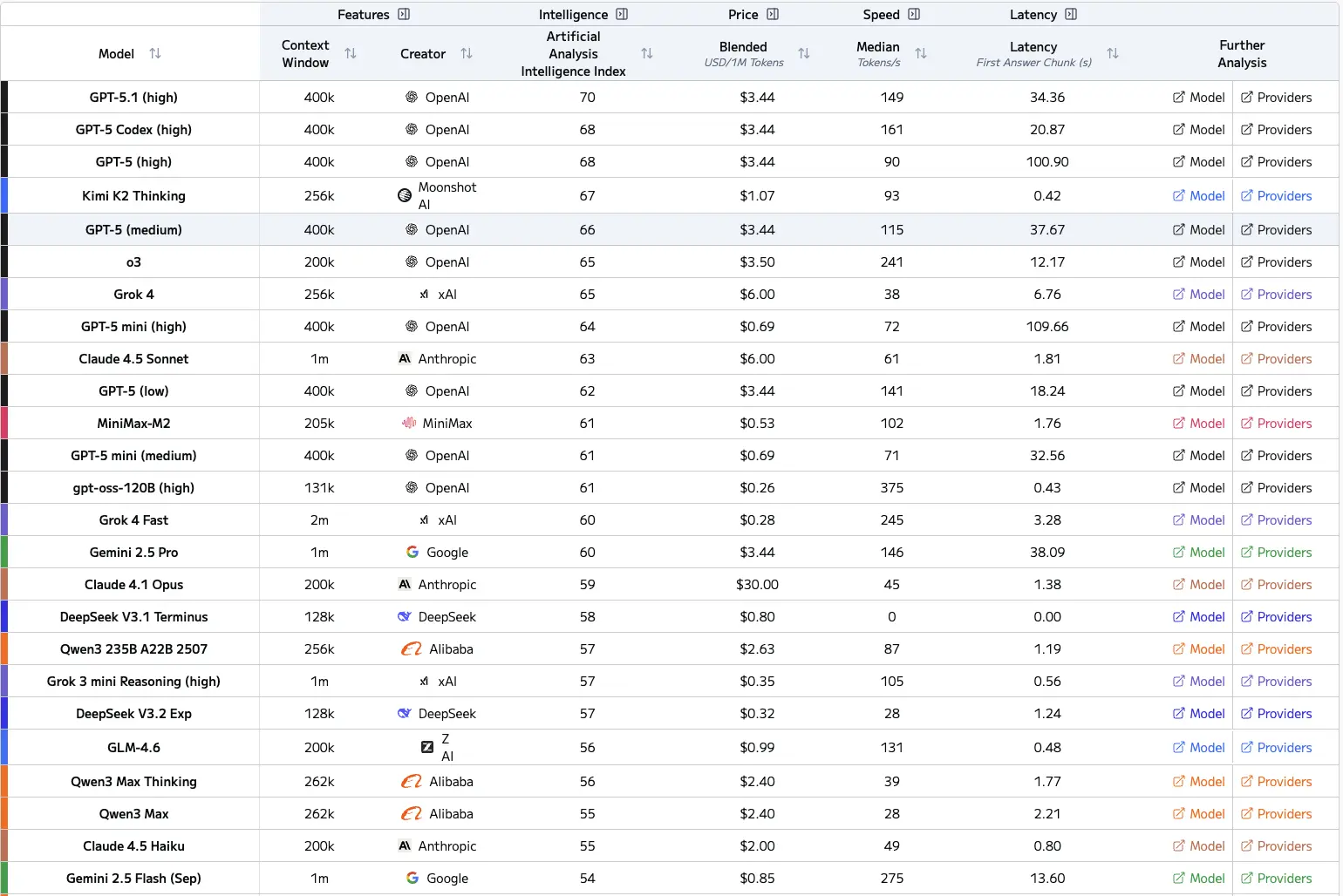
Нижче представлено графік передових LLM для довідки, а також індекс інтелекту
Інструменти для тестування моделей ШІ
Найпростіший спосіб протестувати різні моделі ШІ—використовувати їх поруч. Ось ваші варіанти:
Варіант 1: Відкрити кілька вкладок - Безкоштовно, але дратує. Скопіюйте-вставте свій запит у ChatGPT, Claude та Gemini в окремих вкладках. Порівняйте вручну.
Варіант 2: Використовувати Focus OS від Zemith - Це те, що я побудував спеціально для цієї проблеми. Використовуйте різні моделі всередині наших вкладок FocusOS, дивіться результати поруч з нашою системою вкладок, подібною до Chrome. Ви можете швидко перемикатися між відповідями моделей, не втрачаючи контексту або не жонглюючи вікнами. Економить час і робить порівняння очевидним.
Варіант 3: Доступ до API - Якщо ви технічний, ви можете написати скрипти для програмного тестування моделей ШІ. Добре для масового тестування, але вимагає знань програмування.
Варіант 4: Інші інструменти порівняння - Є кілька інших платформ, таких як Poe або nat.dev, які дозволяють порівнювати моделі, хоча функції різняться.
Ключ—мати систематичний спосіб порівняння моделей ШІ, а не просто стрибати між ними випадково. Focus OS від Zemith робить це дуже простим завдяки своєму інтерфейсу на основі вкладок—думайте про вкладки Chrome, але кожна вкладка—це відповідь різної моделі ШІ на ваш запит.
Поширені помилки при тестуванні моделей ШІ
Я зробив усі ці помилки. Навчіться з мого болю:
Помилка 1: Тестування з різними запитами - Ви трохи змінюєте формулювання для кожної моделі, а потім дивуєтеся, чому результати відрізняються. Використовуйте ідентичні запити.
Помилка 2: Тестування лише один раз - Ви запускаєте один тест і оголошуєте переможця. Моделі ШІ мають варіативність. Тестуйте кілька разів.
Помилка 3: Ігнорування вартості - Ви знаходите "найкращу" модель, але вона коштує у 20 разів більше. Для використання в продакшні важлива вартість за токен.
Помилка 4: Не тестування крайових випадків - Все чудово працює з простими запитами, потім ваш реальний випадок використання ламає все. Тестуйте дивні речі.
Помилка 5: Довіра до суб'єктивного "відчуття" - Вам подобається особистість однієї моделі, тому ви використовуєте її для всього. Це добре для випадкового використання, жахливо для бізнес-рішень.
Помилка 6: Не документування результатів - Ви ретельно тестуєте, але нічого не записуєте. Через три тижні ви не можете згадати, яка модель була кращою для чого.
Скільки часу потрібно для тестування моделей ШІ?
Чесно? Приблизно тиждень реального використання дасть вам 80% того, що вам потрібно знати.
Ось що я рекомендую:
- День 1-2: Протестуйте свої топ 3-5 завдань на всіх моделях. Задокументуйте переможців.
- День 3-5: Використовуйте свого "переможця" для кожного типу завдання в реальній роботі. Відзначте будь-які проблеми.
- День 6-7: Повторно протестуйте все, що не працювало як очікувалося. Скоригуйте свої вибори.
Після цього у вас буде тверде розуміння того, коли до якої моделі звертатися. Ви продовжуватимете вчитися з часом, але початкові інвестиції—це лише тиждень уваги.
Найкращий спосіб тестувати моделі ШІ—не витрачати місяць на формальну оцінку. Це бути навмисним щодо тестування під час вашої нормальної роботи протягом короткого періоду.
Підхід з кількома моделями
Ось що я насправді роблю зараз, і що я рекомендую після того, як ви протестуєте моделі ШІ:
Не намагайтеся вибрати одну "найкращу" модель. Використовуйте різні моделі для різних завдань.
Я використовую ChatGPT для мозкового штурму та перших чернеток креативного контенту. Я використовую Claude, коли мені потрібен ретельний аналіз або редагування. Я використовую Gemini, коли працюю з великими документами або коли мені потрібна поточна інформація з веб-сайту.
Ось чому я побудував Zemith для підтримки кількох моделей. Майбутнє не про пошук однієї ідеальної ШІ—це про наявність правильного інструменту для кожної роботи.
Думайте про це як про наявність різних додатків на телефоні. Ви не використовуєте Instagram для електронної пошти або Gmail для фотографій. Різні інструменти для різних цілей.
Коли ви правильно порівнюєте моделі ШІ та оцінюєте моделі ШІ, ви розумієте, що спеціалізація перемагає узагальнення.
Практичні поради для ефективного тестування моделей ШІ
Почніть з малого: Не намагайтеся протестувати все одразу. Виберіть три загальні завдання та спочатку ретельно їх протестуйте.
Будьте конкретними: Невизначені запити дають невизначені результати. Тестуйте з реальними, конкретними запитами, які ви будете використовувати в реальній роботі.
Тестуйте крайові випадки: Не тестуйте лише щасливий шлях. Спробуйте запити, які є неоднозначними, складними або незвичайними. Там ви побачите реальні відмінності в продуктивності моделі ШІ.
Враховуйте вартість: Деякі моделі дорожчі за інші. Якщо ви виконуєте роботу з великим обсягом, враховуйте ціну під час оцінки моделей ШІ. Трохи гірша модель, яка коштує у 10 разів дешевше, може бути кращим вибором.
Ітеруйте свої запити: Іноді те, що здається слабкістю моделі, насправді є проблемою запиту. Якщо результати не хороші в жодній моделі, перегляньте свій запит.
Залишайтеся в курсі: Моделі постійно покращуються. Те, що правда сьогодні, може змінитися наступного місяця. Періодично повторно тестуйте з важливими випадками використання. Найкращий спосіб тестувати моделі ШІ включає регулярну переоцінку.
Діліться своїми знахідками: Приєднуйтеся до спільнот, де люди обговорюють тестування мовних моделей. Ви навчитеся з досвіду інших і відкриєте випадки використання, які ви не розглядали.
FAQ: Тестування моделей ШІ
Чи потрібні мені технічні навички для тестування моделей ШІ?
Ні. Якщо ви можете копіювати-вставляти текст, ви можете тестувати моделі ШІ. Підхід, який я описав, вимагає нульового програмування або технічних знань.
Який найкращий безкоштовний спосіб тестувати моделі ШІ?
Відкрийте безкоштовні облікові записи для ChatGPT, Claude та Gemini. Використовуйте кілька вкладок. Це незграбно, але працює. Більшість моделей мають безкоштовні рівні, які достатньо хороші для тестування.
Як часто я повинен тестувати моделі ШІ?
Проведіть ретельну оцінку, коли ви вперше почнете використовувати ШІ для роботи. Потім повторно тестуйте кожні 3-4 місяці, коли моделі покращуються. Також тестуйте, коли запускаються нові основні моделі.
Чи можу я взагалі довіряти бенчмаркам моделей ШІ?
Вони не марні, просто обмежені. Бенчмарки говорять вам про теоретичні можливості. Ваше тестування говорить вам про практичну продуктивність для ваших конкретних потреб. Використовуйте обидва.
Чи повинен я тестувати моделі ШІ для кожного завдання?
Ні. Тестуйте свої найпоширеніші завдання та найважливіші завдання. Ви швидко розвинете інтуїцію щодо того, яку модель використовувати для варіацій.
Що робити, якщо "найкраща" модель занадто дорога?
Тоді це насправді не найкраща модель для вас. Найкраща модель—це та, яка дає вам достатньо хороші результати за ціною, яка має сенс для вашого випадку використання.
Суть про те, як тестувати моделі ШІ
Тестування моделей ШІ не повинно бути складним. Вам не потрібна технічна експертиза або фантазійні фреймворки оцінки.
Вам просто потрібно використовувати моделі зі своїми реальними завданнями, порівнювати результати поруч і звертати увагу на те, що працює.
Я бачив, як хтось на Reddit ідеально описав свій процес тестування: "Я стрибав між інструментами ШІ, як пінбол, підживлений кавою. Одну хвилину я прошу Claude переписати абзац, наступну хвилину я відлагоджую з ChatGPT, потім передаю PDF Gemini." Саме так більшість з нас використовує ці інструменти—прагматично, перемикаючись на основі того, що нам потрібно саме зараз.
ШІ, яка дає вам найкращі результати для ваших конкретних потреб—це ваша відповідь. Не та, що має найвищий бал бенчмарку. Не та, про яку всі говорять. Та, яка насправді працює для вас.
Коли ви правильно тестуєте моделі ШІ та порівнюєте моделі ШІ, ви перестаєте покладатися на хайп і починаєте покладатися на дані зі свого власного досвіду.
Ось чому я побудував Zemith. Тому що вибір моделей ШІ повинен базуватися на реальному тестуванні з реальними завданнями, а не на маркетингових заявах або теоретичних бенчмарках.
Спробуйте кілька моделей. Порівняйте їх безпосередньо. Знайдіть, що працює. Це так просто.
І чесно? Ви можете виявити, що використання кількох моделей—кожна для того, що вона робить найкраще—краще, ніж намагатися змусити одну модель робити все.
Це був мій досвід, у будь-якому разі. І я впевнений, що це буде і вашим, коли ви почнете тестувати самостійно.
Хочете легко тестувати моделі ШІ? Перевірте Zemith, де ви можете використовувати ChatGPT, Claude, Gemini та інші поруч з нашим інтерфейсом Focus OS. Універсальний додаток ШІ, який дозволяє перемикатися між відповідями моделей за секунди лише з одним планом підписки
Дослідіть функції Zemith
Весь топовий ШІ. Одна підписка.
ChatGPT, Claude, Gemini, DeepSeek, Grok та 25+ моделей












Завжди активний, ШІ в реальному часі.
Голос + демонстрація екрану · миттєві відповіді
Який найкращий спосіб вивчити нову мову?
Занурення та інтервальне повторення працюють найкраще. Спробуйте щодня споживати контент цільовою мовою.
Голос + трансляція екрану · ШІ відповідає в реальному часі
Генерація зображень
Flux, Nano Banana, Ideogram, Recraft + ще

Пишіть зі швидкістю думки.
ШІ-автодоповнення, перезапис та розширення за командою
Будь-який документ. Будь-який формат.
PDF, URL або YouTube → чат, тест, подкаст та інше
Створення відео
Veo, Kling, MiniMax, Sora + ще

Текст у мовлення
Природні ШІ-голоси, 30+ мов
Генерація коду
Пишіть, налагоджуйте та пояснюйте код
Чат з документами
Завантажте PDF, аналізуйте вміст
Ваш ШІ у кишені.
Повний доступ на iOS та Android · синхронізація скрізь
Ваше нескінченне ШІ-полотно.
Чат, зображення, відео та інструменти руху — поруч
Заощаджуйте години роботи та досліджень
Прості, доступні ціни
Нам довіряють команди в
Безкоштовно
Кредитна картка не потрібна
- 100 кредитів щодня
- 3 моделі ШІ для спроби
- Базовий ШІ-чат
Plus
- 1 000 000 кредитів/місяць
- 25+ моделей ШІ — GPT, Claude, Gemini, Grok та інші
- Agent Mode з веб-пошуком, комп'ютерними інструментами та іншим
- Creative Studio: генерація зображень та відео
- Project Library: чат з документами, вебсайтами та YouTube, створення подкастів, картки для запам'ятовування, звіти та інше
- Workflow Studio та FocusOS
Professional
- Усе, що в Plus, а також:
- 2 100 000 кредитів/місяць
- Ексклюзивні Pro-моделі (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools та Max Mode
- Перший доступ до найновіших функцій
- Доступ до додаткових пропозицій