
如何测试AI模型:您需要的唯一指南(2025)
学习如何使用我们的6步框架测试ChatGPT、Claude和Gemini等AI模型。使用真实任务并排比较AI模型——无需技术技能。
如何测试AI模型:您真正需要的唯一指南
大约一年前,我在构建Zemith时开始痴迷地测试AI模型。不是因为我是ML研究员——我不是。而是因为我一直被炒作所欺骗。
每个人都说GPT-4是最好的。然后Claude出现了,人们说那个是最好的。然后是Gemini。然后某个新模型会发布,突然那个就成了王者。目标不断移动,我意识到:如果您想知道哪个AI模型真正适合您的需求,您必须自己测试AI模型。
不是阅读基准测试。不是相信营销声明。真正测试它们。
这不是关于困惑度分数或BLEU指标的技术指南。这是真实的人——创始人、创作者、开发者、任何每天使用AI的人——应该如何评估AI模型并找出哪个真正有效。
虽然有些人更喜欢查看图表进行比较,但通常实际的世界结果差异很大。唯一能确定模型响应内容和方式的方法是通过实际使用测试。
为什么自己测试AI模型是不可协商的
这是我艰难学到的:AI模型基准测试对您的实际工作基本上没用。
一个模型可能在某个学术测试中占主导地位,但这并不能告诉您它是否会以您的语气写邮件,理解您行业的行话,或处理您的业务每天处理的奇怪边缘情况。
我一直在阅读Reddit上关于AI模型的讨论,有一个反复出现的主题:有人问"我应该使用哪个AI?"而回答到处都是。一个人发誓Claude在编码方面是无敌的。另一个人说ChatGPT更有创意。还有人坚持认为Gemini最准确。他们都对,也都错了。
在测试这些模型数千次之后,真相是:没有单一的"最佳"AI模型。每个都有不同的优势,这些优势根据您实际尝试做的事情而重要性不同。
ChatGPT可能会给您创意、引人入胜的内容,感觉像人类。Claude可能会提供更适合分析的结构化、深思熟虑的回应。Gemini在事实研究方面表现出色,并且有巨大的上下文窗口用于长文档。
知道哪个模型最适合您的唯一方法是使用您的实际用例测试AI模型。不是假设的。不是通用的提示。您的真实工作。
每个人真正在问的问题
在我们进入如何测试AI模型之前,让我解决我在Reddit和DM中不断看到的问题:
"我可以只使用ChatGPT做所有事情吗?"
您可以,但您会错过很多。这就像使用瑞士军刀,有时您真的需要一把合适的螺丝刀。
"基准测试还不够吗?"
不太够。我看到一个Reddit帖子,有人指出Claude在某个基准测试中得分较低,但给了他们更好的代码解释。基准测试衡量研究人员认为重要的东西,而不是实际帮助您完成工作的东西。
"我如何知道一个回应是否比另一个更好?"
这是真正的问题,老实说,比您想象的更简单。如果您可以使用答案更好地、更快地或更少挫折地完成您的任务——那就是您的答案。
"这不是想太多了吗?"
也许,如果您随意使用AI。但如果您正在建立业务、每天写内容,或依赖AI进行实际工作?测试不是想太多——这是尽职调查。
如何测试AI模型:6步框架
忘记技术指标。以下是实际测试语言模型和以有意义的方式比较AI模型的方法:
1. 从您的实际任务开始
不要用像"写一个关于猫的故事"这样的通用提示测试AI模型。那没用。
相反,抓住三到五个您实际经常做的任务:
- 起草您经常发送的特定类型的邮件
- 总结您工作中的典型文档
- 为您的实际项目生成想法
- 为您实际构建的东西编写代码
- 回答您收到的客户支持问题
这些任务越具体和真实,您的AI模型评估就会越好。
2. 在不同AI模型中使用相同的提示
这在您测试AI模型时至关重要。取完全相同的提示,通过ChatGPT、Claude、Gemini和您正在考虑的任何其他模型运行它。
不要改变措辞。不要为每个模型调整它。使用相同的输入,以便您可以公平地比较输出。
当我第一次在Zemith这样做时,我很震惊。对于创意头脑风暴,ChatGPT一致地给我更有趣的角度。对于分析数据或分解复杂主题,Claude更清晰、更有条理。对于当前信息的事实研究,Gemini领先。
我看到一个很棒的Reddit帖子,有人用同一个谜语测试了所有三个模型:"医生的儿子的父亲怎么可能不是医生?"所有三个都答对了,但它们的方法完全不同。Claude给出了最详细的分解,甚至指出了我们思考问题方式的潜在偏见。ChatGPT简洁明了。Gemini给出了正确答案和简短解释。
都正确,都有用,但每个都有不同的风格。当您决定在实际工作中使用哪一个时,这种差异很重要。
3. 并排比较,而不是从记忆中
人类记忆在比较方面很糟糕。如果您今天测试ChatGPT,明天测试Claude,您会忘记每个说了什么的细微差别。
这正是我在Zemith上构建FocusOS的原因,因为试图记住哪个模型在多个标签页中说了什么是噩梦。
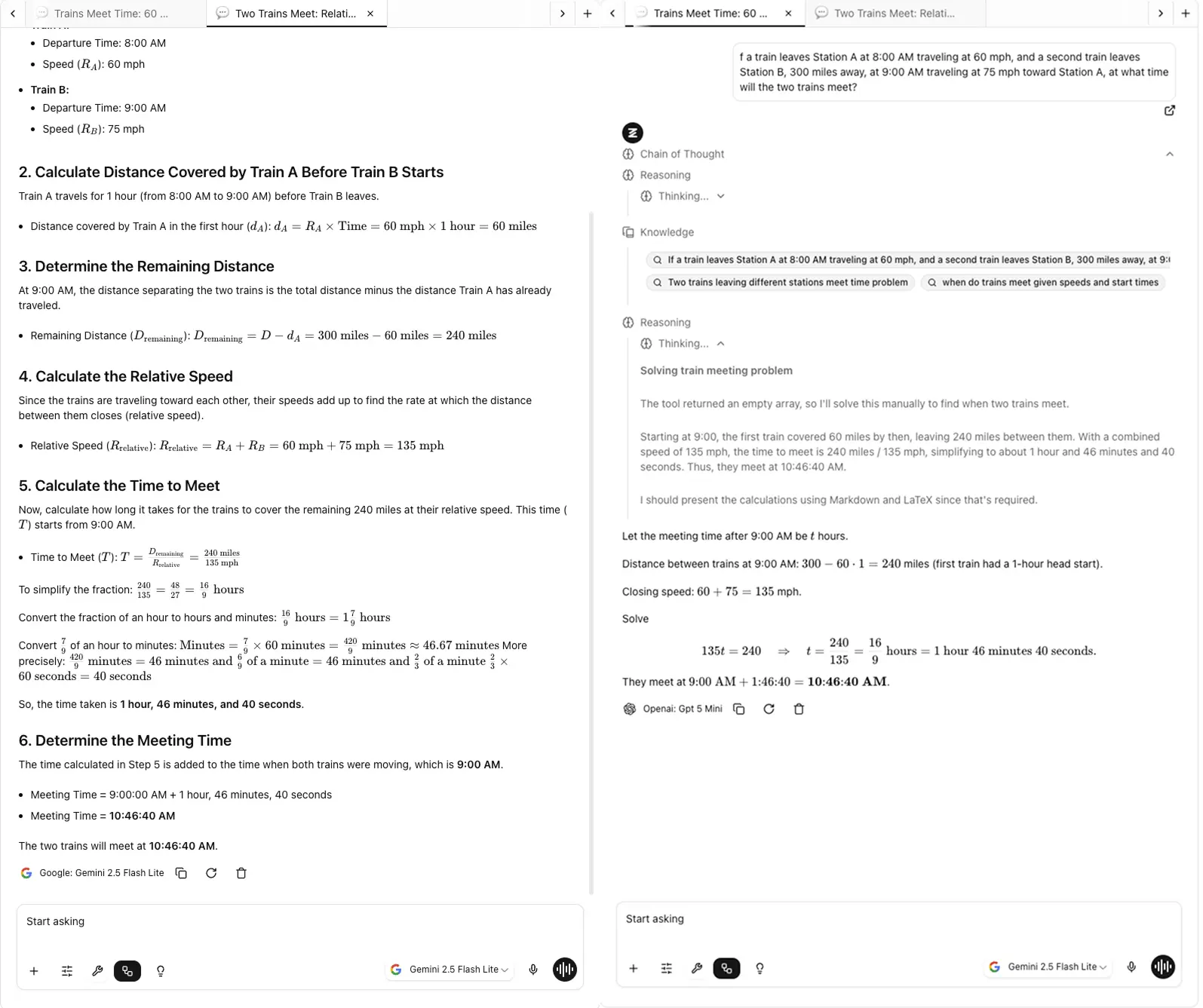
在Zemith,我设计了Focus OS,带有类似Chrome的标签系统,这样您可以快速切换标签,而不会丢失一个页面的上下文,无需在浏览器标签之间切换,不会丢失哪个答案来自哪个模型的跟踪。
一起查看回应会揭示您否则会错过的模式:
- 哪个模型实际回答了您的问题vs.哪个在漫谈?
- 哪个保持了您喜欢的语气?
- 哪个给了您实际可以使用的信息?
这是测试AI模型的最佳方法,因为您实时看到差异,而不是试图从记忆中重建它们。
4. 测试一致性和AI模型性能
通过每个模型运行相同的提示几次。AI模型是概率性的——它们不总是给出相同的答案。
有些模型比其他模型更一致。如果您将AI用于生产工作或面向客户的内容,一致性很重要。您不希望一个回应很棒,下一个却很平庸。
当您评估AI模型时,一致性是基准测试无法很好捕捉的关键指标。
5. 检查幻觉和准确性
如果您将AI用于任何事实性的东西,这一点尤其重要。
AI模型有时会自信地编造东西。它们会引用不存在的研究,引用产品没有的功能,或陈述完全错误的"事实"。
通过询问您知道正确答案的问题来测试这一点,或通过要求模型引用来源。然后验证这些来源确实存在并说了模型声称的内容。
在我测试语言模型的经验中,它们在这方面差异很大。有些比其他更容易产生自信的幻觉,您需要知道哪些可以信任用于事实工作。
6. 记录您的结果
记录什么有效,什么无效。您未来的自己会感谢您。您也可以在Zemith笔记中保存笔记,通过转到笔记页面或在FocusOS中再次打开新的笔记标签
我保留一个简单的电子表格:
- 任务类型
- 我测试了哪些模型
- 获胜者及原因
- 任何显著的差异
以这种方式测试AI模型几周后,模式就会出现。您将开始看到哪个模型在哪种类型的任务中一致获胜。
比较AI模型时要寻找什么
当您盯着来自三个不同模型的回应时,以下是对您的AI模型评估真正重要的:
回应质量:它是否实际回答了您问的问题?信息准确吗?它是完整的,还是遗漏了重要方面?
语气和风格:它是否匹配您想要的声音?有些模型更正式,其他更随意。我注意到Claude往往更谨慎和深思熟虑。ChatGPT可以更有活力和对话性。一位Reddit用户说ChatGPT变得"更有吸引力和讨人喜欢",但警告说这使它成为一个"复杂的应声虫",同意一切。如果您需要真正的批评,您必须明确要求。
深度vs.简洁:您需要全面的解释还是简洁的答案?不同的模型默认不同的详细程度。我在所有三个中测试了相同的提示——ChatGPT给了我可以在瞥一眼时阅读的最简洁答案,Claude提供了分步说明,Gemini给出了没有步骤的概述。
创意vs.准确性:对于创意任务,您可能想要意想不到的想法。对于分析工作,您想要精确。为一个优化的模型通常在另一个方面有困难。
速度:如果您交互式地使用AI,响应时间很重要。当我测试AI模型时,速度在模型之间甚至同一模型的不同版本之间差异很大。
它是否实际引用来源?:如果您在做研究,这一点很重要。Gemini在提供实际来源链接方面一致更好。ChatGPT有时会给您过时的信息(免费版本只知道到2023年底)。Claude历史上在链接来源方面不太好,当您需要验证某些东西时这很令人沮丧。
AI模型比较:我测试数千个提示学到的
以下是我在比较不同用例的AI模型时注意到的模式:
对于写作和内容创作
ChatGPT在创意、引人入胜的内容方面表现出色。它非常适合博客文章、营销文案和任何需要个性的东西。一位测试Twitter钩子的用户说"它们都不太好",但Claude给出了最好的结果——不太冗长,没有不必要的标签。
当您需要深思熟虑、细致入微的写作或想要紧密匹配特定风格时,Claude更好。我用它来编辑我的写作,特别是当我先给它我最好作品的例子时。
对于编码
当您并排测试AI模型时,这就是事情变得有趣的地方。
在我看到的测试中,当被要求"创建一个功能齐全的俄罗斯方块游戏"时,Claude构建了一个华丽、功能齐全的游戏,带有分数和控制。ChatGPT创建了一个基本但有效的。Gemini做得很好,但没有达到Claude的水平。
然而,Claude Sonnet的成本是Gemini Flash的20倍。如果您正在构建一个成本很重要的AI产品,Gemini可能是更明智的选择。Claude在复杂任务方面一致产生更清晰的代码和更好的文档。
对于研究和总结
Gemini以其巨大的上下文窗口而闪耀,往往更准确。它可以消化巨大的文档并高效地提取关键信息。
一位测试了所有三个的评论者发现Gemini是"最一致的全能者",在事实、上下文查询方面特别强。它还有实际的内置网络搜索,不像Claude。
对于推理和问题解决
推理模型(如OpenAI的o1)系统地分解复杂问题。它们非常适合规划、策略和多步思考。但它们更慢——有时需要几分钟才能响应。
对于分析和解释
当您为此目的评估AI模型时,Claude提供结构化、逻辑分析。它特别擅长分解复杂想法并清楚地解释它们。几位Reddit用户提到Claude非常适合"深思熟虑、平衡的论点",特别是在有争议的话题上。
记忆因素
这是我在测试语言模型时让我惊讶的事情——在2025年,只有ChatGPT有记忆。它记住跨对话的关于您的细节。Gemini和Claude没有。
如果您需要一个记住您的偏好、您的项目、您的写作风格的AI,从会话到会话,ChatGPT目前是您唯一的选择。我发现这很疯狂,因为它创造了这些"神奇时刻",ChatGPT根据过去的对话建议事情。
ChatGPT vs Claude vs Gemini:快速比较
| 功能 | ChatGPT | Claude | Gemini |
|---|---|---|---|
| 最适合 | 创意内容,一般任务 | 代码,分析,编辑 | 研究,长文档 |
| 优势 | 引人入胜的语气,记忆 | 结构化思维,清晰代码 | 事实准确性,上下文 |
| 弱点 | 可能是"应声虫" | 无记忆,较少来源 | 创意较少 |
| 上下文窗口 | 128K tokens | 200K tokens | 1M tokens |
| 网络搜索 | 通过插件 | 内置 | 内置 |
| 成本 | 中等 | 最高 | 最低(Flash) |
| 速度 | 快 | 快 | 变化 |
但这是最重要的洞察:您的里程会有所不同。对我的用例有效的东西可能对您不起作用。这就是为什么您需要使用自己的提示测试AI模型。
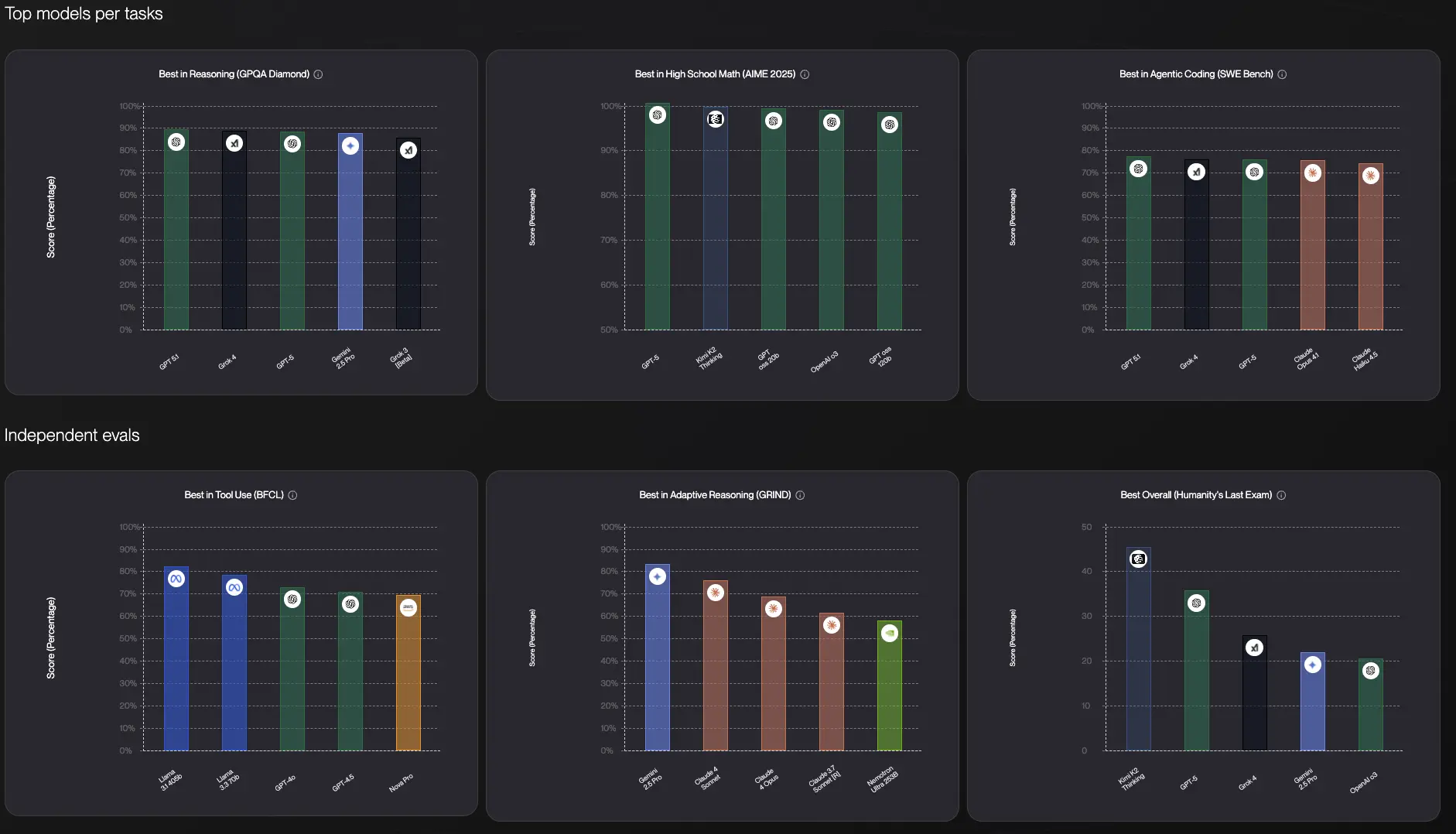
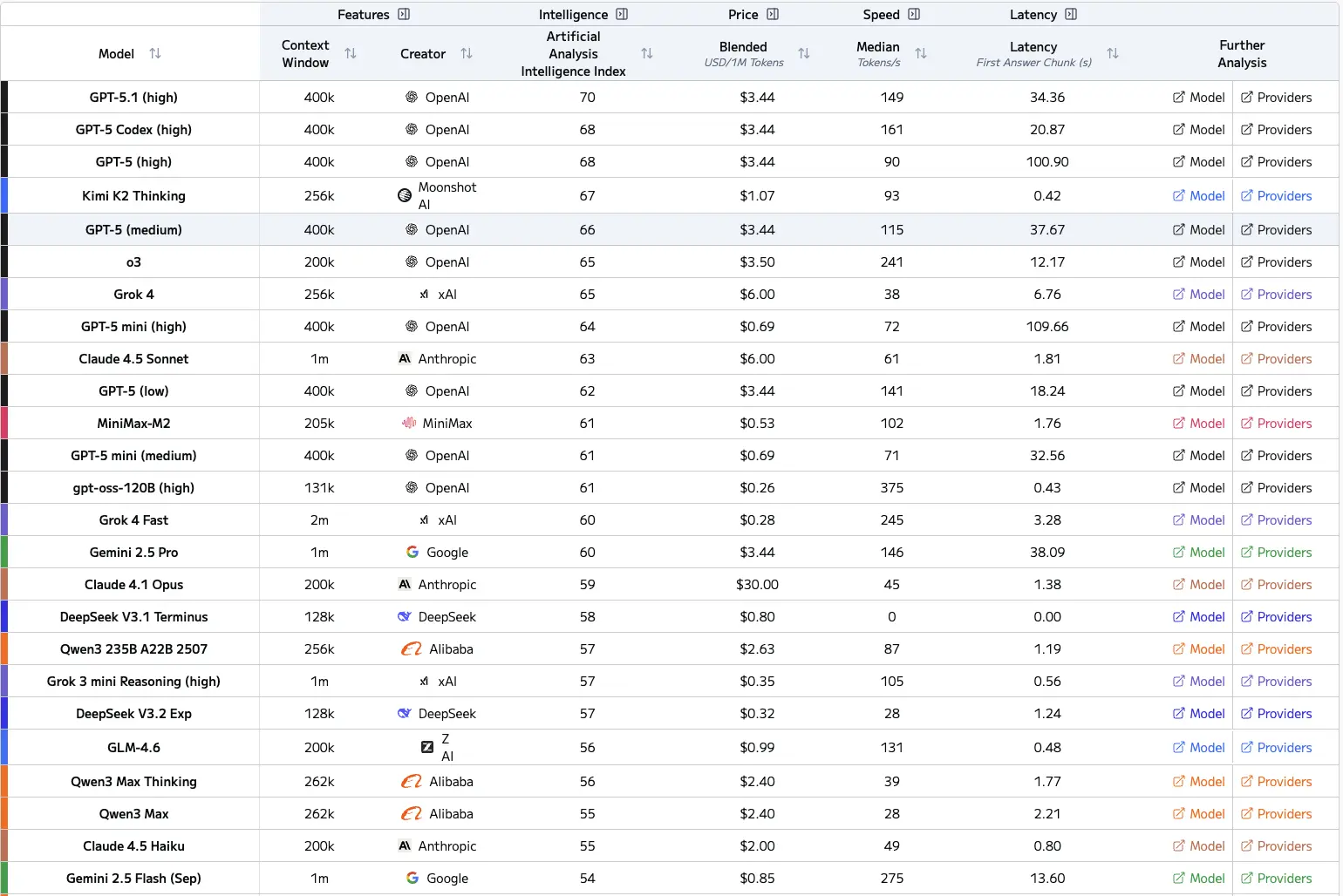
下面代表了前沿LLM的图表以供参考,包括智能指数
测试AI模型的工具
测试不同AI模型的最简单方法是并排使用它们。以下是您的选项:
选项1:打开多个标签 - 免费但烦人。将您的提示复制粘贴到ChatGPT、Claude和Gemini的单独标签中。手动比较。
选项2:使用Zemith的Focus OS - 这是我专门为解决这个问题而构建的。在我们的FocusOS标签中使用不同的模型,通过我们类似Chrome的标签系统并排查看结果。您可以快速在模型响应之间切换,而不会丢失上下文或处理窗口。节省时间并使比较明显。
选项3:API访问 - 如果您是技术人员,您可以编写脚本以编程方式测试AI模型。适合批量测试,但需要编码知识。
选项4:其他比较工具 - 还有其他一些平台如Poe或nat.dev可以让您比较模型,尽管功能各不相同。
关键是有一个系统的方法来比较AI模型,而不仅仅是在它们之间随机跳转。Zemith的Focus OS通过其基于标签的界面使这变得非常简单——想想Chrome标签,但每个标签是不同AI模型对您提示的响应。
测试AI模型时的常见错误
我犯了所有这些错误。从我的痛苦中学习:
错误1:使用不同的提示测试 - 您为每个模型稍微改变措辞,然后想知道为什么结果不同。使用相同的提示。
错误2:只测试一次 - 您运行一次测试并宣布获胜者。AI模型有可变性。测试多次。
错误3:忽略成本 - 您找到"最佳"模型,但它成本高20倍。对于生产使用,每个token的成本很重要。
错误4:不测试边缘情况 - 简单提示一切都很棒,然后您的真实用例破坏一切。测试奇怪的东西。
错误5:信任主观"感觉" - 您喜欢一个模型的个性,所以您用它做所有事情。这对于随意使用来说很好,对于业务决策来说很糟糕。
错误6:不记录结果 - 您彻底测试但不写下任何东西。三周后,您不记得哪个模型在什么方面更好。
测试AI模型需要多长时间?
老实说?大约一周的实际使用会给您80%的所需信息。
以下是我推荐的:
- 第1-2天:在所有模型中测试您的顶级3-5个任务。记录获胜者。
- 第3-5天:在实际工作中使用每个任务类型的"获胜者"。注意任何问题。
- 第6-7天:重新测试任何没有按预期工作的东西。调整您的选择。
之后,您将对何时使用哪个模型有扎实的感觉。您会随着时间的推移继续学习,但初始投资只是一周的关注。
测试AI模型的最佳方法不是花一个月进行正式评估。而是在您的正常工作中在短时间内有意地进行测试。
多模型方法
以下是我现在实际做的,以及我建议在您测试AI模型之后:
不要试图选择一个"最佳"模型。为不同任务使用不同模型。
我使用ChatGPT进行头脑风暴和创意内容的第一稿。当我需要仔细分析或编辑时,我使用Claude。当处理大文档或需要来自网络的当前信息时,我使用Gemini。
这就是为什么我构建Zemith以支持多个模型。未来不是找到完美的AI——而是为每个工作拥有正确的工具。
想想它就像在手机上拥有不同的应用程序。您不使用Instagram发邮件或Gmail拍照。不同目的的不同工具。
当您正确比较AI模型和评估AI模型时,您意识到专业化胜过泛化。
有效测试AI模型的实用技巧
从小开始:不要试图一次测试所有东西。选择三个常见任务并首先彻底测试它们。
具体:模糊的提示给出模糊的结果。使用您在实际工作中会使用的实际、具体提示进行测试。
测试边缘情况:不要只测试快乐路径。尝试模糊、复杂或不寻常的提示。这就是您会看到AI模型性能真正差异的地方。
考虑成本:有些模型比其他模型更昂贵。如果您正在进行高量工作,在评估AI模型时考虑定价。一个稍微差一点但成本低10倍的模型可能是更好的选择。
迭代您的提示:有时看似模型弱点实际上是提示问题。如果任何模型的结果都不好,修改您的提示。
保持更新:模型不断改进。今天真实的东西可能下个月就会改变。定期重新测试重要用例。测试AI模型的最佳方法包括定期重新评估。
分享您的发现:加入人们讨论测试语言模型的社区。您将从他人的经验中学习,并发现您没有考虑过的用例。
常见问题:测试AI模型
我需要技术技能来测试AI模型吗?
不需要。如果您可以复制粘贴文本,您可以测试AI模型。我概述的方法需要零编码或技术知识。
测试AI模型的最佳免费方法是什么?
为ChatGPT、Claude和Gemini打开免费账户。使用多个标签。它很笨拙但有效。大多数模型都有足够用于测试的免费层级。
我应该多久测试一次AI模型?
当您第一次开始将AI用于工作时进行彻底评估。然后随着模型改进每3-4个月重新测试。也在新的主要模型发布时测试。
我可以信任AI模型基准测试吗?
它们不是无用的,只是有限的。基准测试告诉您理论能力。您的测试告诉您针对您特定需求的实际性能。两者都使用。
我应该为每个任务测试AI模型吗?
不。测试您最常见的任务和最重要的任务。您会快速培养对哪个模型用于变化的直觉。
如果"最佳"模型太贵怎么办?
那么它实际上不是您的最佳模型。最佳模型是在对您的用例有意义的价格下给您足够好结果的模型。
关于如何测试AI模型的底线
测试AI模型不必复杂。您不需要技术专业知识或花哨的评估框架。
您只需要使用模型处理您的实际任务,并排比较结果,并注意什么有效。
我看到有人在Reddit上完美地描述了他们的测试过程:"我一直在AI工具之间跳来跳去,就像咖啡因驱动的弹球。一分钟我在问Claude重写一段,下一分钟我用ChatGPT调试,然后把PDF交给Gemini。"这正是我们大多数人使用这些工具的方式——实用地,根据我们当时需要的切换。
为您特定需求提供最佳结果的AI——那就是您的答案。不是基准分数最高的。不是每个人都在谈论的。实际为您提供服务的那个。
当您正确测试AI模型并比较AI模型时,您停止依赖炒作,开始依赖来自您自己经验的数据。
这就是为什么我构建Zemith。因为选择AI模型应该基于真实任务的真实测试,而不是营销声明或理论基准。
尝试多个模型。直接比较它们。找到有效的。就这么简单。
老实说?您可能会发现使用多个模型——每个用于它最擅长的——比试图强迫一个模型做所有事情更好。
无论如何,这是我的经验。我打赌一旦您开始自己测试,它也会是您的。
想以简单的方式测试AI模型吗?查看Zemith,您可以在我们的Focus OS界面中并排使用ChatGPT、Claude、Gemini等。一体式AI应用程序,让您在几秒钟内在模型响应之间切换,只需一个订阅计划
探索 Zemith 功能
所有顶级AI。一个订阅。
ChatGPT、Claude、Gemini、DeepSeek、Grok 及25+模型












始终在线,实时AI。
语音 + 屏幕共享 · 即时回答
学习一门新语言的最佳方式是什么?
沉浸式学习和间隔重复效果最好。尝试每天消费目标语言的媒体内容。
语音 + 屏幕共享 · AI 实时回答
图像生成
Flux、Nano Banana、Ideogram、Recraft + 更多

以思维的速度书写。
AI自动补全、改写和按命令扩展
任何文档。任何格式。
PDF、URL或YouTube → 聊天、测验、播客等
视频创作
Veo、Kling、MiniMax、Sora + 更多

文字转语音
自然AI语音,30+语言
代码生成
编写、调试和解释代码
与文档对话
上传PDF,分析内容
口袋里的AI。
iOS和Android完整访问 · 随处同步
你的无限AI画布。
聊天、图像、视频和动态工具 — 并排展示
节省数小时的工作和研究时间
简单、经济实惠的定价
受信赖的企业团队
免费
无需信用卡
- 每日100积分
- 3个AI模型试用
- 基础AI聊天
增强版
- 1,000,000积分/月
- 25+个AI模型 — GPT、Claude、Gemini、Grok等
- Agent Mode:网页搜索、计算机工具等
- Creative Studio:图像生成和视频生成
- Project Library:与文档、网站和YouTube对话,播客生成、闪卡、报告等
- Workflow Studio和FocusOS
专业版
- 包含增强版所有功能,以及:
- 2,100,000积分/月
- Pro专属模型(Claude Opus、Grok 4、Sonar Pro)
- Motion Tools和Max Mode
- 优先使用最新功能
- 访问额外优惠