Mastering Database Design Principles
Explore essential database design principles to build fast, scalable, and reliable systems. This guide covers data modeling, normalization, and indexing.
Database design principles are essentially the rules of the road for organizing information. They're the best practices we follow to make sure data is stored logically, correctly, and without unnecessary duplication. Getting these principles right from the start is the first real step toward building software that's both reliable and built to last.
Why Great Database Design Is Not Negotiable
Long before you type a single line of code, the fate of your application is often decided by its foundation—the database. Think of it like the blueprint for a skyscraper. If that blueprint is flawed, it doesn't matter how strong your steel or concrete is; the building is doomed to have problems.
The same is true for software. A poorly designed database will inevitably lead to a sluggish application, constant data errors, and a nightmare when it comes time to grow. This isn't just about theory; it's about avoiding a mountain of technical debt down the road. A well-planned database directly boosts your application’s most important qualities.
- Application Speed: When data is organized logically, the database can find what it needs in a flash. This translates directly to a faster, smoother experience for your users.
- Data Integrity: A good design enforces rules that keep your data accurate and consistent. It's what stops nonsensical information, like an order with a negative price, from ever making it into the system.
- Scalability and Maintenance: A clean structure is just plain easier to work with. When you need to add a new feature or handle more traffic, the process is straightforward instead of requiring a massive, risky overhaul.
The Origins of Structured Data
This need for structure isn't a new concept. The foundational ideas of database design really started taking shape in the 1960s as we moved away from simple, flat file storage. This was the era when Charles Bachman developed the first real database management system, the Integrated Data Store (IDS).
IBM later adopted his model, which was a huge turning point for managing data with computers. These early "navigational" databases required you to follow pointers from one record to the next to find information. While clunky by today's standards, they established the very first methods for organizing data that would eventually evolve into the principles we rely on today. You can to see how these early systems paved the way for modern tech.
A database is only as good as its design. Without a solid blueprint, even the most powerful hardware and sophisticated code will eventually be brought to its knees by data chaos and inefficiency.
Ultimately, understanding these core concepts is what separates a professional, durable application from one that's destined to fail. While tools like and its AI coding assistants can definitely speed up the development process, they work best when they're building on top of a fundamentally solid database structure. This guide will walk you through the essentials of data modeling, normalization, and performance tuning to give you that critical foundation.
From Business Idea To Database Blueprint
Every great application starts with an idea, not a line of code. But how do you get from a vague business concept to a functional system? You need a bridge—something that translates your goals into a tangible data structure. This is precisely where the art of database design comes into play, turning abstract ideas into a logical blueprint for developers.

The primary tool for this job is the Entity-Relationship Diagram (ERD). Think of it as the architectural drawing for your data. An ERD gives you a visual map of what information you need to store and, just as importantly, how all those pieces of information connect. It gets everyone, from stakeholders to the dev team, on the same page from the get-go.
Identifying Your Core Entities
First things first, you need to pinpoint your core entities. In database-speak, an entity is just a noun—a person, place, object, or concept you need to keep track of. Let's imagine we're building a simple e-commerce store. What are the essential building blocks?
You'd quickly land on a few key entities:
- Customers: The people buying your stuff.
- Products: The items you're selling.
- Orders: The transactions that connect a customer to a product.
With your entities listed, you then define their attributes. These are just the specific details about each entity. For a 'Customer', you’d probably want to know their FirstName, LastName, and EmailAddress. For a 'Product', you’d need a ProductName, Price, and Description. Simple as that.
Mapping Relationships Between Entities
Now for the fun part. With your entities and attributes defined, you map the relationships between them. These connections are the verbs that describe how your nouns interact, and getting them right is absolutely fundamental to good database design. You'll generally run into three main types.
A one-to-one (1:1) relationship is the rarest. It’s when one instance of an entity is linked to exactly one instance of another. For example, a User might have one and only one UserProfile. You can't have a user with two profiles, and you can't have a profile that belongs to two users.
Much more common is the one-to-many (1:M) relationship. This is when one record in a table can link to many records in another. Think about it: a single Customer can place many Orders over time, but each Order belongs to only one Customer. That's a classic 1:M scenario.
Finally, we have the many-to-many (M:N) relationship. This happens when multiple records in one table can be associated with many records in another. An Order can contain multiple Products, and a single Product can, of course, appear in many different Orders.
An ERD acts as the definitive source of truth for your data model. By visualizing entities, attributes, and their relationships, you eliminate ambiguity and create a robust foundation that prevents costly structural changes later in the development cycle.
This initial planning stage is a crucial part of effective , as it ensures your information is structured logically right from the start.
The Junction Table Solution
So, how do you handle a many-to-many relationship in a standard relational database? The answer is a clever little tool called a junction table (sometimes called an associative table). Back in our e-commerce store, we'd create a new table—let's call it OrderItems—that sits right between Orders and Products.
This OrderItems table doesn't hold much on its own. Its main job is to hold a key pointing to the Orders table and another key pointing to the Products table. In doing so, it neatly breaks down that messy M:N relationship into two clean 1:M relationships. This elegant design perfectly models how things work in the real world and is a cornerstone of applying database principles effectively. When you master this kind of conceptual modeling, you're not just drawing boxes and lines; you're building a blueprint for data integrity and future scalability.
Organizing Your Data With Normalization
Once you have a conceptual blueprint for your database, like an Entity-Relationship Diagram, the real work begins. The next step is to refine that structure through a process called normalization. While the term sounds academic, it’s really just a methodical way to clean up your data tables.
Think of it like organizing a horribly messy closet. You're not just making it look neat; you're making everything easy to find, preventing future messes, and ensuring you don't have five of the same shirt scattered in different places.
Why Bother With Normalization?
The main reason we normalize is to hunt down and eliminate data redundancy—storing the same piece of information in multiple places. It might seem harmless at first, but redundancy is the root cause of what we call data anomalies. These are strange inconsistencies that pop up when you try to update, add, or delete information.
For example, if a customer's address is stored with every single one of their 10 orders, what happens when they move? You’d have to find and update all 10 records perfectly. Miss just one, and you’ve created an inconsistency. Normalization fixes this by giving every piece of data a single, definitive home. It makes your database more efficient, reliable, and much easier to manage as it grows.
This process is similar to how you’d for a smoother workflow. Applying normalization principles brings that same clarity and predictability to your application's data.
The infographic below shows how normalization takes messy, repeated data and progressively refines it into a clean, logical structure by applying the first three normal forms.
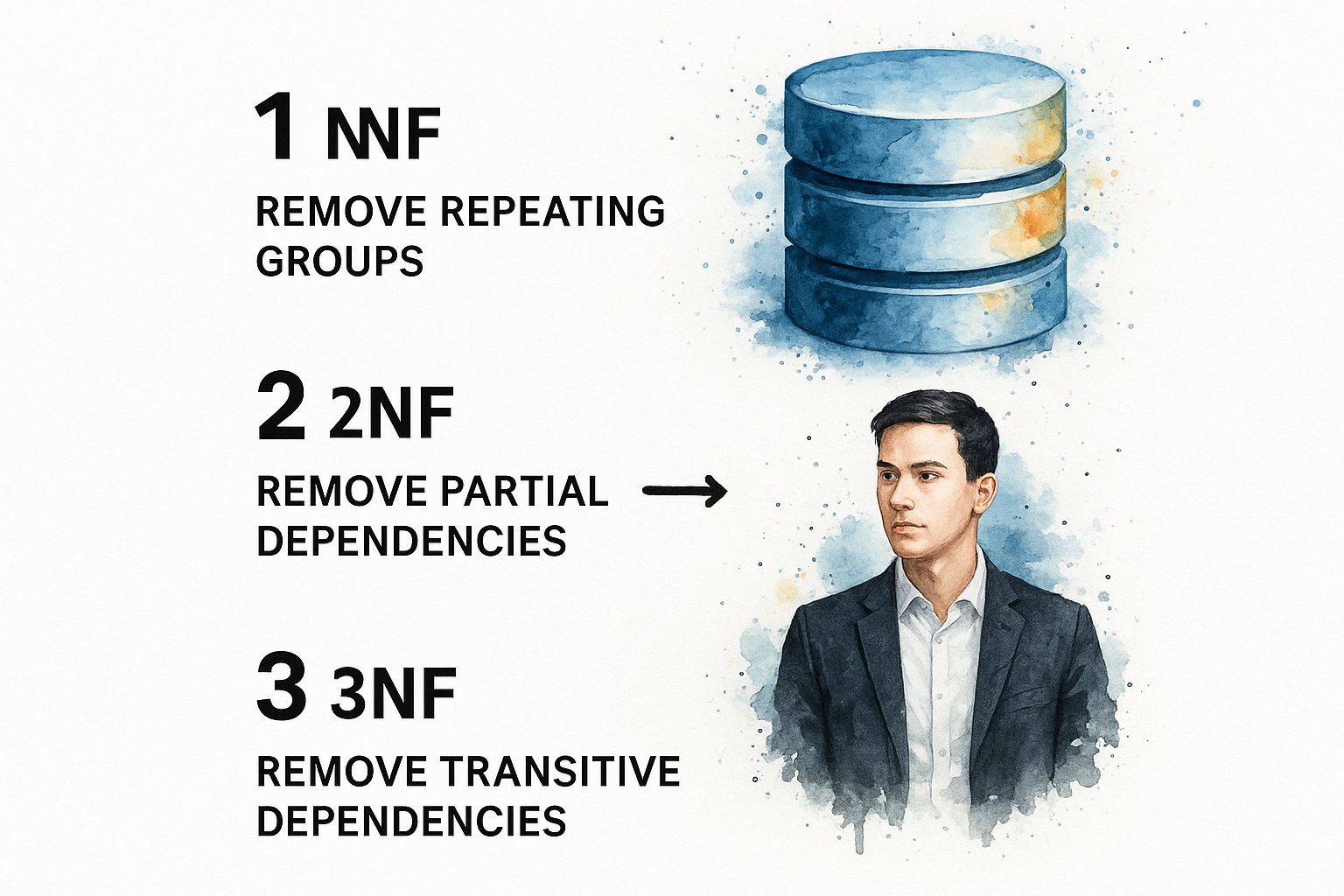
As you can see, each step systematically removes a specific type of problematic dependency, leading to a much more resilient data model.
First Normal Form (1NF): Eliminating Repeating Groups
Our journey starts with the First Normal Form (1NF). The rule here is beautifully simple: every column in a table must hold a single, atomic value, and every record needs to be unique. "Atomic" just means the value can't be broken down into smaller parts.
It also means no repeating groups of columns, like Product1, Product2, and Product3.
Let's imagine a messy Orders table. A single row might try to cram multiple products into one cell, like "Keyboard, Mouse, Monitor". This breaks 1NF because the product column contains a list, not a single value. To fix this, you would create a separate row for each item in the order. The OrderID is repeated, but now every cell contains just one piece of information.
Second Normal Form (2NF): Removing Partial Dependencies
Once your tables are in 1NF, the next stop is the Second Normal Form (2NF). This rule comes into play when you have a composite primary key—a key made from two or more columns combined.
The rule for 2NF is this: the table must be in 1NF, and every non-key column must depend on the entire primary key, not just a piece of it. We're getting rid of what's known as partial dependencies.
In our Orders example, the primary key might now be OrderID + ProductID. If we also had a ProductDescription column in that same table, we'd have a problem. The description depends only on the ProductID, not the OrderID. That's a partial dependency.
A partial dependency creates a data integrity risk. If the very last order for a particular product is deleted, the product's description—which lives in the order item table—could be lost forever.
To achieve 2NF, you move the partially dependent data out. You’d create a new Products table with ProductID as its key, and that's where ProductDescription would live. The original table, maybe now called OrderItems, just holds the keys (OrderID, ProductID) that link everything together.
Third Normal Form (3NF): Removing Transitive Dependencies
Finally, we reach the Third Normal Form (3NF). A table is in 3NF if it's already in 2NF and contains no transitive dependencies. A transitive dependency is when a non-key column depends on another non-key column instead of the primary key itself.
Let's go back to our Orders table. Imagine it contains CustomerID and also CustomerCity. In this case, CustomerCity depends on CustomerID, which in turn depends on the primary key, OrderID. The city has no direct relationship with the order—it’s related to the customer who placed the order.
That's a classic transitive dependency. To clean this up and hit 3NF, you'd move all the customer-specific info into its own Customers table. This table would have CustomerID as its primary key, along with columns like CustomerName and CustomerCity. The Orders table just needs to hold the CustomerID to link back to the right record.
Understanding Normal Forms With a Practical Example
To bring this all together, let's trace how a single, messy table transforms as we apply these rules. This table shows the progression from a jumbled state to a clean, 3NF structure.
This clean separation is the hallmark of a well-designed database. It ensures your data is logically organized, resilient to anomalies, and ready to scale.
Connecting Your Data With Keys and Relationships
Okay, so you've gone through the process of normalization and now you have these clean, well-organized tables. That's a huge step. But right now, they're just separate islands of data. The real magic happens when you build bridges between them, and that's exactly what keys and relationships are for.
They are the "relational" part of a relational database, turning disconnected lists into a powerful, interconnected system.

Without these connections, your database can't answer complex questions. You could look up a customer or a product, but you couldn't easily ask, "Which customers bought this specific product?" The two most important tools we use to build these bridges are primary keys and foreign keys.
The Role of the Primary Key
Every single table needs one column (or a combination of columns) that can uniquely identify every single row. No exceptions. This is the table's primary key. It's the ultimate guarantee that you'll never confuse one record for another.
Think of a Students table at a university. The primary key would be the Student ID number. Just like your driver's license number is unique to you, a Student ID is unique to one student. When you pull up record #1138, you know you're looking at one specific person, and only them. This principle is a non-negotiable cornerstone of good database design.
The Role of the Foreign Key
If a primary key gives a record its unique identity, a foreign key is how you reference that identity in a different table. This is how you actually create the link.
Let's stick with the university example. Imagine you have a ClassRosters table. Instead of re-typing a student's name, major, and other details for every class they enroll in, you just use their Student ID. That StudentID column in the ClassRosters table is a foreign key. It points directly back to the primary key in the Students table, creating a clear, efficient relationship.
Primary Key: A unique, non-null ID for a record within its own table. (e.g.,
StudentIDin theStudentstable). Foreign Key: A field in one table that points to the Primary Key in another table, creating the link. (e.g.,StudentIDin theClassRosterstable).
This setup is brilliant because it helps maintain data integrity. If a student drops out and their record is removed from the Students table, the database can be configured to automatically prevent their ID from being left behind in any class rosters. No more "ghost" records or inconsistent data.
Choosing Your Keys Wisely: Natural vs. Surrogate
When you're picking a primary key, you generally have two paths you can take.
- Natural Keys: This is when you use an attribute that already exists in the real world and is naturally unique. Think of a Social Security Number or a user's email address. The upside is that the key has real-world meaning. The downside? Real-world data can change. What if someone changes their email? You'd have a massive headache updating that key in every single table that references it.
- Surrogate Keys: This is an artificial key you create just for the purpose of being a unique ID. It has no business meaning. The classic example is an auto-incrementing integer (1, 2, 3...). The value is generated by the database and it never changes. It might feel a bit abstract, but that stability is priceless, which is why surrogate keys are the go-to choice in well over 90% of modern databases.
For development teams, building on a solid data foundation is everything. While collaborative platforms like provide an excellent workspace for building applications, the strength and reliability of those apps are deeply rooted in these fundamental database principles.
Defining Keys in a Real Database
So how do you actually implement this? Moving from your ERD diagram to a real database means writing a little SQL. Here’s what it looks like for our university example.
First, we create the Students table with a surrogate primary key.
CREATE TABLE Students ( StudentID INT PRIMARY KEY AUTO_INCREMENT, FirstName VARCHAR(50), LastName VARCHAR(50), Email VARCHAR(100) UNIQUE );
Next, we create the ClassRosters table and use a foreign key to connect it back to Students.
CREATE TABLE ClassRosters ( RosterID INT PRIMARY KEY AUTO_INCREMENT, ClassID INT, StudentID INT, FOREIGN KEY (StudentID) REFERENCES Students(StudentID) );
That one line—FOREIGN KEY (StudentID) REFERENCES Students(StudentID)—is where the enforcement happens. It's a direct command to the database: "Do not allow a StudentID to be inserted here unless it already exists as a primary key in the Students table." This simple constraint is how you build a reliable, interconnected, and self-validating data system from the ground up.
Designing For Speed With Indexing Strategies
A perfectly normalized database is great, but if it's slow, it’s a failure. After you’ve organized your data’s structure, the next critical step is making sure your application can pull that data out in a flash. This is where we shift from thinking about data integrity to pure performance, and the most powerful tool you have for this is indexing.
Think of it like trying to find a specific topic in a massive book that has no index. You'd be stuck flipping through every single page, one by one. In database terms, this painful process is called a "full table scan," and it's just as slow as it sounds.
An index is the database equivalent of a book's index. It's a special, separate lookup table that points directly to the location of the data you need, allowing the database to jump straight to the right spot without searching the entire table.
What to Index and When
The secret to a good indexing strategy is being selective. You don't just index everything; that can cause more harm than good. Instead, you index strategically, targeting the columns that will give you the most bang for your buck.
So, what are the best candidates?
- Primary Keys: These are almost always indexed automatically. They are the main way the database finds a unique row, so an index is a must.
- Foreign Keys: Any column you use to connect tables is a prime candidate. Indexing foreign keys makes
JOINoperations, which are the bread and butter of relational databases, dramatically faster. - Frequently Searched Columns: If your application constantly lets users search by
LastNameor filter products byCategory, those are the columns you want to index.
But here’s the catch: indexing isn’t a free lunch. It speeds up reading data, but it slows down writing data.
Every time you add, update, or delete a record, the database doesn't just change the table—it has to update every single index associated with it. Piling on too many indexes can turn a simple write operation into a sluggish, resource-hogging nightmare.
This trade-off is at the heart of performance tuning. An application that's read-heavy, like a blog or an online store, will benefit from having more indexes. On the other hand, a write-heavy system, like a real-time logging service, needs a much more conservative approach to keep data flowing in quickly.
Beyond the Basic Index
While indexing is the star of the show, a few other design choices can give you a serious speed boost.
One of the simplest is choosing efficient data types. Why use a massive integer type to store a number that will never go above 100? Using the smallest data type that fits your needs saves space on disk and in memory, which makes everything run a little bit faster.
Another powerful, though more advanced, technique is to strategically break the rules of normalization. This is called denormalization, and it involves deliberately adding redundant data to avoid slow, complex joins. For example, a social media feed needs to show a post and the user's name instantly. Instead of joining the posts and users tables every single time, you might store the username directly in the posts table. It’s a calculated compromise you make only when a real performance bottleneck has been identified.
These ideas aren't new. In the early days of databases, when storage was incredibly expensive, normalized designs could reduce data redundancy by up to 50%. The standardization of SQL, which eventually saw compliance rates hit over 90% among major vendors, allowed these principles to be applied universally. You can discover more about the evolution of database standards to see how these foundational ideas have shaped the technology we use today.
For teams who want to optimize performance without all the manual guesswork, modern tools can handle much of the heavy lifting. Platforms like offer automated performance monitoring and query optimization, helping to turn complex database tuning into a far more manageable process. This helps ensure your application stays fast and responsive as it grows, all while being built on the timeless principles of sound database design.
Applying Timeless Principles In The Modern Era
The path from a high-level Entity-Relationship Diagram to a fine-tuned, physical database is paved with three core ideas: integrity, efficiency, and scalability. These aren't dusty old concepts from a forgotten textbook; they're more critical today than ever, shaping how we build data systems across every technology imaginable.

Many of these foundational principles were hammered out back in the 1970s. This was the decade that gave us the relational model, a revolutionary idea that decoupled the logical structure of data from its physical storage. This led to game-changers like IBM’s System R, which brought SQL into the world and set the standard for how we talk to our data.
Enduring Concepts In A NoSQL World
It's easy to think that the rise of NoSQL, cloud databases, and distributed systems has made these old-school relational ideas irrelevant. Nothing could be further from the truth. The tools have evolved, but the underlying goals of managing data well haven't budged an inch.
Think about it. Whether you're carefully defining a rigid schema in PostgreSQL or crafting a flexible JSON document in MongoDB, you're still making crucial decisions about how to organize information. The objective is always the same: keep data consistent, stamp out redundancy, and build for the specific performance profile your application demands.
For a closer look at how these ideas play out in the real world, it's worth exploring these .
The medium changes, but the message remains the same. A well-designed NoSQL document that prevents internal data duplication is simply the modern expression of the classic principle of normalization.
Building Modern Applications On A Solid Foundation
Ultimately, a firm grasp of these principles gives you the power to build systems that are both resilient and ready to grow, no matter what technology you're using. It's about applying a time-tested way of thinking to today's challenges.
For example, the same logic that guides a strong relational schema also underpins the creation of effective knowledge management systems, which depend entirely on structured, easy-to-find information. The actionable insight here is that by using a tool like Zemith to document your database schemas, you are not just building code—you are building a reusable knowledge base for your entire team.
By starting with a solid foundation, you can innovate and build quickly without sacrificing the long-term stability that only comes from respecting these core tenets of data design.
Common Questions We Hear About Database Design
As you start applying these ideas, you're bound to run into some tricky situations. Let's walk through a few of the questions that come up all the time.
What’s the Single Most Important Design Principle?
If I had to pick just one, it would be data integrity. Everything else flows from this.
Think of it as the foundation of a house. If your data isn't accurate, consistent, and reliable, the whole application built on top of it is unstable. This means getting your data model right, normalizing correctly to stop weird inconsistencies from creeping in, and using keys to lock your relationships in place. A lightning-fast database is worthless if the data it serves is wrong.
Is It Ever Okay to Break the Rules of Normalization?
Yes, but you need a very good reason. This is a technique called denormalization, and it's almost always about boosting performance in applications that do a lot more reading than writing.
Imagine a critical report that's painfully slow because it has to pull data from a dozen different tables. In that scenario, you might decide to strategically add some duplicate data to one or two tables just to speed that specific query up.
Be warned, though: this is a trade-off. You're sacrificing a bit of "purity" for speed. Denormalization uses more storage and makes updates a headache because you have to change the same data in multiple places. Only do it when you've pinpointed a real performance bottleneck.
Do These Principles Still Apply to NoSQL Databases?
They absolutely do, just in a different way. The core thinking is the same, even if the tools have changed.
With a NoSQL database like or , you aren't normalizing across tables. Instead, you're designing your JSON documents or data structures to prevent duplicating information within them.
The fundamental goals never change: model your real-world entities accurately, keep your data consistent, and design for how your application will actually use the data. Whether you're writing SQL queries or fetching documents, these concepts are your bedrock.
Building your application on a solid foundation is the surest path to creating something that lasts. When you're ready to build, Zemith offers an all-in-one AI-powered workspace with advanced coding assistants and research tools to help you design and develop robust, scalable applications faster. You can .
Explore Zemith Features
Every top AI. One subscription.
ChatGPT, Claude, Gemini, DeepSeek, Grok & 25+ more












Always on, real-time AI.
Voice + screen share · instant answers
What's the best way to learn a new language?
Immersion and spaced repetition work best. Try consuming media in your target language daily.
Voice + screen share · AI answers in real time
Image Generation
Flux, Nano Banana, Ideogram, Recraft + more

Write at the speed of thought.
AI autocomplete, rewrite & expand on command
Any document. Any format.
PDF, URL, or YouTube → chat, quiz, podcast & more
Video Creation
Veo, Kling, Grok Imagine and more

Text to Speech
Natural AI voices, 30+ languages
Code Generation
Write, debug & explain code
Chat with Documents
Upload PDFs, analyze content
Your AI, in your pocket.
Full access on iOS & Android · synced everywhere
Your infinite AI canvas.
Chat, image, video & motion tools — side by side
Save hours of work and research
Transparent, High-Value Pricing
Trusted by teams at
Free
No credit card required
- 100 credits daily
- 3 AI models to try
- Basic AI chat
Plus
- 1,000,000 credits/month
- 25+ AI models — GPT, Claude, Gemini, Grok & more
- Agent Mode with web search, computer tools and more
- Creative Studio: image generation and video generation
- Project Library: chat with document, website and youtube, podcast generation, flashcards, reports and more
- Workflow Studio and FocusOS
Professional
- Everything in Plus, and:
- 2,100,000 credits/month
- Pro-exclusive models (Claude Opus, Grok 4, Sonar Pro)
- Motion Tools & Max Mode
- First access to latest features
- Access to additional offers
What Our Users Say
Great Tool after 2 months usage
"I love the way multiple tools they integrated in one platform. Going in the right direction."
— simplyzubair
Best in Kind!
"The quality of data and sheer speed of responses is outstanding. I use this app every day."
— barefootmedicine
Simply awesome
"The credit system is fair, models are perfect, and the discord is very responsive. Quite awesome."
— MarianZ
Great for Document Analysis
"Just works. Simple to use and great for working with documents. Money well spent."
— yerch82
Great AI site with accessible LLMs
"The organization of features is better than all the other sites — even better than ChatGPT."
— sumore
Excellent Tool
"It lives up to the all-in-one claim. All the necessary functions with a well-designed, easy UI."
— AlphaLeaf
Well-rounded platform with solid LLMs
"The team clearly puts their heart and soul into this platform. Really solid extra functionality."
— SlothMachine
Best AI tool I've ever used
"Updates made almost daily, feedback is incredibly fast. Just look at the changelogs — consistency."
— reu0691